
Dynamic Task Mapping¶
Dynamic Task Mapping allows a way for a workflow to create a number of tasks at runtime based upon current data, rather than the DAG author having to know in advance how many tasks would be needed.
This is similar to defining your tasks in a for loop, but instead of having the DAG file fetch the data and do that itself, the scheduler can do this based on the output of a previous task. Right before a mapped task is executed the scheduler will create n copies of the task, one for each input.
It is also possible to have a task operate on the collected output of a mapped task, commonly known as map and reduce.
Simple mapping¶
In its simplest form you can map over a list defined directly in your DAG file using the expand() function instead of calling your task directly.
from datetime import datetime
from airflow import DAG
from airflow.decorators import task
with DAG(dag_id="simple_mapping", start_date=datetime(2022, 3, 4)) as dag:
@task
def add_one(x: int):
return x + 1
@task
def sum_it(values):
total = sum(values)
print(f"Total was {total}")
added_values = add_one.expand(x=[1, 2, 3])
sum_it(added_values)
This will show Total was 9 in the task logs when executed.
This is the resulting DAG structure:
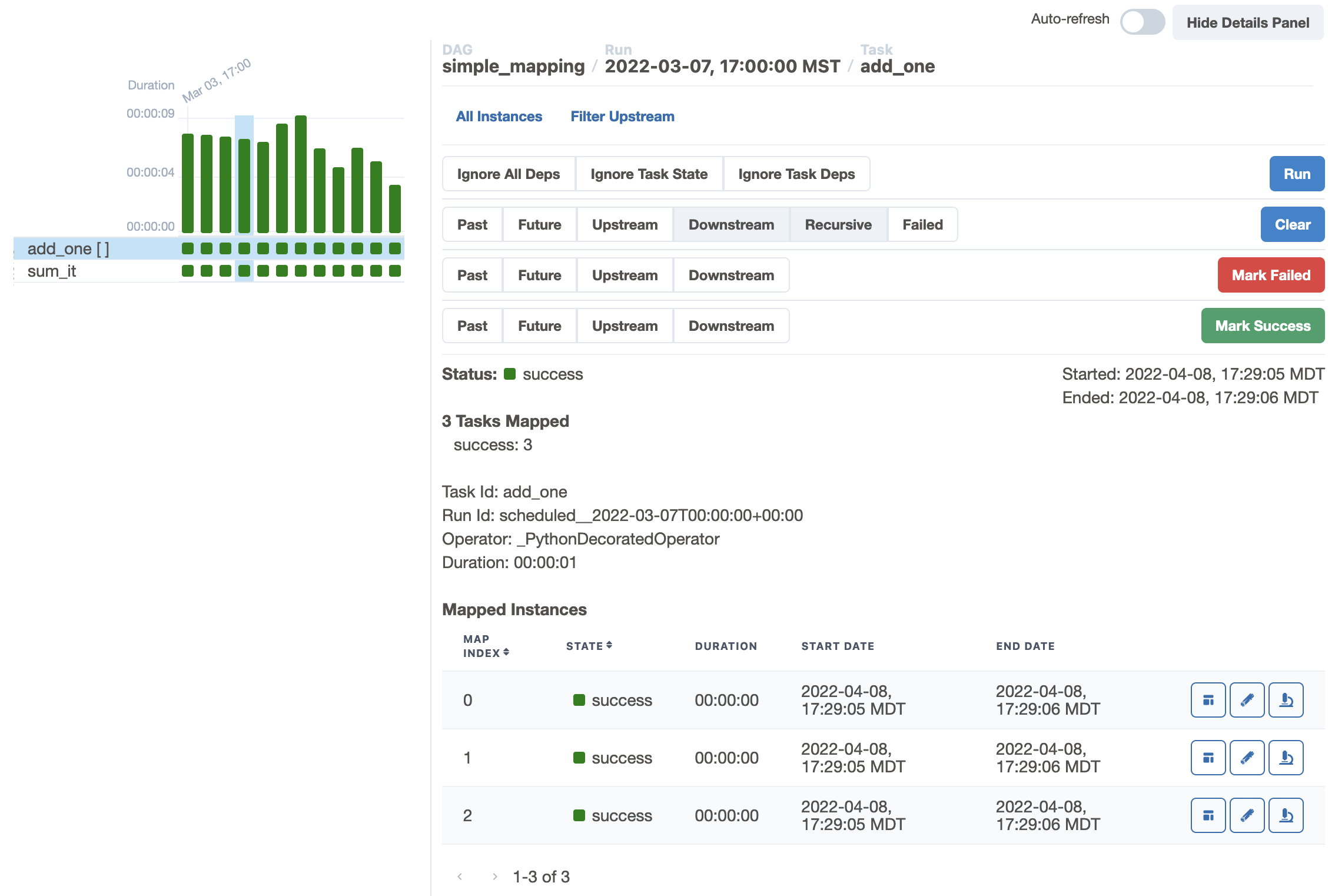
The grid view also provides visibility into your mapped tasks in the details panel:
Note
Only keyword arguments are allowed to be passed to expand().
Note
Values passed from the mapped task is a lazy proxy
In the above example, values received by sum_it is an aggregation of all values returned by each mapped instance of add_one. However, since it is impossible to know how many instances of add_one we will have in advance, values is not a normal list, but a “lazy sequence” that retrieves each individual value only when asked. Therefore, if you run print(values) directly, you would get something like this:
_LazyXComAccess(dag_id='simple_mapping', run_id='test_run', task_id='add_one')
You can use normal sequence syntax on this object (e.g. values[0]), or iterate through it normally with a for loop. list(values) will give you a “real” list, but please be aware of the potential performance implications if the list is large.
Note
A reduce task is not required.
Although we show a “reduce” task here (sum_it) you don’t have to have one, the mapped tasks will still be executed even if they have no downstream tasks.
Repeated Mapping¶
The result of one mapped task can also be used as input to the next mapped task.
with DAG(dag_id="repeated_mapping", start_date=datetime(2022, 3, 4)) as dag:
@task
def add_one(x: int):
return x + 1
first = add_one.expand(x=[1, 2, 3])
second = add_one.expand(x=first)
This would have a result of [3, 4, 5].
Constant parameters¶
As well as passing arguments that get expanded at run-time, it is possible to pass arguments that don’t change – in order to clearly differentiate between the two kinds we use different functions, expand() for mapped arguments, and partial() for unmapped ones.
@task
def add(x: int, y: int):
return x + y
added_values = add.partial(y=10).expand(x=[1, 2, 3])
# This results in add function being expanded to
# add(x=1, y=10)
# add(x=2, y=10)
# add(x=3, y=10)
This would result in values of 11, 12, and 13.
This is also useful for passing things such as connection IDs, database table names, or bucket names to tasks.
Mapping over multiple parameters¶
As well as a single parameter it is possible to pass multiple parameters to expand. This will have the effect of creating a “cross product”, calling the mapped task with each combination of parameters.
@task
def add(x: int, y: int):
return x + y
added_values = add.expand(x=[2, 4, 8], y=[5, 10])
# This results in the add function being called with
# add(x=2, y=5)
# add(x=2, y=10)
# add(x=4, y=5)
# add(x=4, y=10)
# add(x=8, y=5)
# add(x=8, y=10)
This would result in the add task being called 6 times. Please note however that the order of expansion is not guaranteed.
It is not possible to achieve an effect similar to Python’s zip function with mapped arguments.
Task-generated Mapping¶
Up until now the examples we’ve shown could all be achieved with a for loop in the DAG file, but the real power of dynamic task mapping comes from being able to have a task generate the list to iterate over.
@task
def make_list():
# This can also be from an API call, checking a database, -- almost anything you like, as long as the
# resulting list/dictionary can be stored in the current XCom backend.
return [1, 2, {"a": "b"}, "str"]
@task
def consumer(arg):
print(list(arg))
with DAG(dag_id="dynamic-map", start_date=datetime(2022, 4, 2)) as dag:
consumer.expand(arg=make_list())
The make_list task runs as a normal task and must return a list or dict (see What data types can be expanded?), and then the consumer task will be called four times, once with each value in the return of make_list.
Mapping with non-TaskFlow operators¶
It is possible to use partial and expand with classic style operators as well. Some arguments are not mappable and must be passed to partial(), such as task_id, queue, pool, and most other arguments to BaseOperator.
BashOperator.partial(task_id="bash", do_xcom_push=False).expand(
bash_command=["echo 1", "echo 2"]
)
Note
Only keyword arguments are allowed to be passed to partial().
Mapping over result of classic operators¶
If you want to map over the result of a classic operator you will need to create an XComArg object manually.
from airflow import XComArg
task = MyOperator(task_id="source")
downstream = MyOperator2.partial(task_id="consumer").expand(input=XComArg(task))
Putting it all together¶
In this example you have a regular data delivery to an S3 bucket and want to apply the same processing to every file that arrives, no matter how many arrive each time.
from datetime import datetime
from airflow import DAG, XComArg
from airflow.decorators import task
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
from airflow.providers.amazon.aws.operators.s3 import S3ListOperator
with DAG(dag_id="mapped_s3", start_date=datetime(2020, 4, 7)) as dag:
files = S3ListOperator(
task_id="get_input",
bucket="example-bucket",
prefix='incoming/provider_a/{{ data_interval_start.strftime("%Y-%m-%d") }}',
)
@task
def count_lines(aws_conn_id, bucket, file):
hook = S3Hook(aws_conn_id=aws_conn_id)
return len(hook.read_key(file, bucket).splitlines())
@task
def total(lines):
return sum(lines)
counts = count_lines.partial(aws_conn_id="aws_default", bucket=files.bucket).expand(
file=XComArg(files)
)
total(lines=counts)
What data types can be expanded?¶
Currently it is only possible to map against a dict, a list, or one of those types stored in XCom as the result of a task.
If an upstream task returns an unmappable type, the mapped task will fail at run-time with an UnmappableXComTypePushed exception. For instance, you can’t have the upstream task return a plain string – it must be a list or a dict.
How do templated fields and mapped arguments interact?¶
All arguments to an operator can be mapped, even those that do not accept templated parameters.
If a field is marked as being templated and is mapped, it will not be templated.
For example, this will print {{ ds }} and not a date stamp:
@task
def make_list():
return ["{{ ds }}"]
@task
def printer(val):
print(val)
printer.expand(val=make_list())
If you want to interpolate values either call task.render_template yourself, or use interpolation:
@task
def make_list(ds):
return [ds]
@task
def make_list(**context):
return [context["task"].render_template("{{ ds }}", context)]
Placing limits on mapped tasks¶
There are two limits that you can place on a task:
the number of mapped task instances can be created as the result of expansion.
The number of the mapped task can run at once.
Limiting number of mapped task
The [core]
max_map_lengthconfig option is the maximum number of tasks thatexpandcan create – the default value is 1024.If a source task (
make_listin our earlier example) returns a list longer than this it will result in that task failing.Limiting parallel copies of a mapped task
If you wish to not have a large mapped task consume all available runner slots you can use the
max_active_tis_per_dagsetting on the task to restrict how many can be running at the same time.Note however that this applies to all copies of that task against all active DagRuns, not just to this one specific DagRun.
@task(max_active_tis_per_dag=16) def add_one(x: int): return x + 1 BashOperator.partial(task_id="my_task", max_active_tis_per_dag=16).expand( bash_command=commands )
Automatically skipping zero-length maps¶
If the input is empty (zero length), no new tasks will be created and the mapped task will be marked as SKIPPED.