Tasks¶
A Task is the basic unit of execution in Airflow. Tasks are arranged into DAGs, and then have upstream and downstream dependencies set between them into order to express the order they should run in.
There are three basic kinds of Task:
Operators, predefined task templates that you can string together quickly to build most parts of your DAGs.
Sensors, a special subclass of Operators which are entirely about waiting for an external event to happen.
A TaskFlow-decorated
@task, which is a custom Python function packaged up as a Task.
Internally, these are all actually subclasses of Airflow's BaseOperator, and the concepts of Task and Operator are somewhat interchangeable, but it's useful to think of them as separate concepts - essentially, Operators and Sensors are templates, and when you call one in a DAG file, you're making a Task.
Relationships¶
The key part of using Tasks is defining how they relate to each other - their dependencies, or as we say in Airflow, their upstream and downstream tasks. You declare your Tasks first, and then you declare their dependencies second.
There are two ways of declaring dependencies - using the >> and << (bitshift) operators:
first_task >> second_task >> [third_task, fourth_task]
Or the more explicit set_upstream and set_downstream methods:
first_task.set_downstream(second_task)
third_task.set_upstream(second_task)
These both do exactly the same thing, but in general we recommend you use the bitshift operators, as they are easier to read in most cases.
By default, a Task will run when all of its upstream (parent) tasks have succeeded, but there are many ways of modifying this behaviour to add branching, only wait for some upstream tasks, or change behaviour based on where the current run is in history. For more, see Control Flow.
Tasks don't pass information to each other by default, and run entirely independently. If you want to pass information from one Task to another, you should use XComs.
Task Instances¶
Much in the same way that a DAG is instantiated into a DAG Run each time it runs, the tasks under a DAG are instantiated into Task Instances.
An instance of a Task is a specific run of that task for a given DAG (and thus for a given execution_date). They are also the representation of a Task that has state, representing what stage of the lifecycle it is in.
The possible states for a Task Instance are:
none: The Task has not yet been queued for execution (its dependencies are not yet met)scheduled: The scheduler has determined the Task's dependencies are met and it should runqueued: The task has been assigned to an Executor and is awaiting a workerrunning: The task is running on a worker (or on a local/synchronous executor)success: The task finished running without errorsfailed: The task had an error during execution and failed to runskipped: The task was skipped due to branching, LatestOnly, or similar.upstream_failed: An upstream task failed and the Trigger Rule says we needed itup_for_retry: The task failed, but has retry attempts left and will be rescheduled.up_for_reschedule: The task is a Sensor that is inreschedulemodesensing: The task is a Smart Sensorremoved: The task has vanished from the DAG since the run started
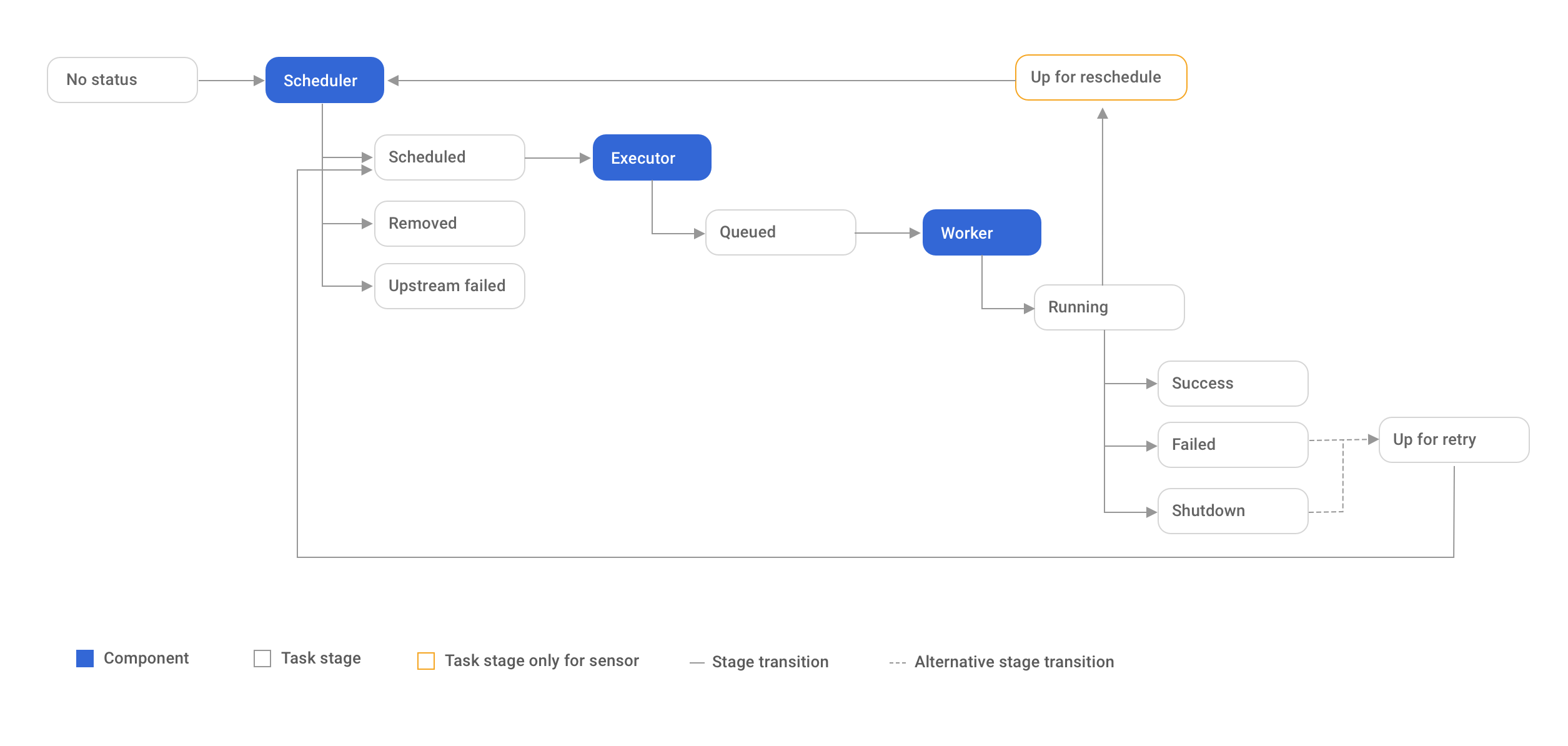
Ideally, a task should flow from none, to scheduled, to queued, to running, and finally to success.
When any custom Task (Operator) is running, it will get a copy of the task instance passed to it; as well as being able to inspect task metadata, it also contains methods for things like XComs.
Relationship Terminology¶
For any given Task Instance, there are two types of relationships it has with other instances.
Firstly, it can have upstream and downstream tasks:
task1 >> task2 >> task3
When a DAG runs, it will create instances for each of these tasks that are upstream/downstream of each other, but which all have the same execution_date.
There may also be instances of the same task, but for different values of execution_date - from other runs of the same DAG. We call these previous and next - it is a different relationship to upstream and downstream!
Note
Some older Airflow documentation may still use "previous" to mean "upstream". If you find an occurrence of this, please help us fix it!
Timeouts¶
If you want a task to have a maximum runtime, set its execution_timeout attribute to a datetime.timedelta value that is the maximum permissible runtime. If it runs longer than this, Airflow will kick in and fail the task with a timeout exception.
If you merely want to be notified if a task runs over but still let it run to completion, you want SLAs instead.
SLAs¶
An SLA, or a Service Level Agreement, is an expectation for the maximum time a Task should take. If a task takes longer than this to run, then it visible in the "SLA Misses" part of the user interface, as well going out in an email of all tasks that missed their SLA.
Tasks over their SLA are not cancelled, though - they are allowed to run to completion. If you want to cancel a task after a certain runtime is reached, you want Timeouts instead.
To set an SLA for a task, pass a datetime.timedelta object to the Task/Operator's sla parameter. You can also supply an sla_miss_callback that will be called when the SLA is missed if you want to run your own logic.
If you want to disable SLA checking entirely, you can set check_slas = False in Airflow's [core] configuration.
To read more about configuring the emails, see Email Configuration.
Special Exceptions¶
If you want to control your task's state from within custom Task/Operator code, Airflow provides two special exceptions you can raise:
AirflowSkipExceptionwill mark the current task as skippedAirflowFailExceptionwill mark the current task as failed ignoring any remaining retry attempts
These can be useful if your code has extra knowledge about its environment and wants to fail/skip faster - e.g., skipping when it knows there's no data available, or fast-failing when it detects its API key is invalid (as that will not be fixed by a retry).
Zombie/Undead Tasks¶
No system runs perfectly, and task instances are expected to die once in a while. Airflow detects two kinds of task/process mismatch:
Zombie tasks are tasks that are supposed to be running but suddenly died (e.g. their process was killed, or the machine died). Airflow will find these periodically, clean them up, and either fail or retry the task depending on its settings.
Undead tasks are tasks that are not supposed to be running but are, often caused when you manually edit Task Instances via the UI. Airflow will find them periodically and terminate them.
Executor Configuration¶
Some Executors allow optional per-task configuration - such as the KubernetesExecutor, which lets you set an image to run the task on.
This is achieved via the executor_config argument to a Task or Operator. Here's an example of setting the Docker image for a task that will run on the KubernetesExecutor:
MyOperator(...,
executor_config={
"KubernetesExecutor":
{"image": "myCustomDockerImage"}
}
)
The settings you can pass into executor_config vary by executor, so read the individual executor documentation in order to see what you can set.