Dynamic Task Mapping
Dynamic Task Mapping allows a way for a workflow to create a number of tasks at runtime based upon current data, rather than the Dag author having to know in advance how many tasks would be needed.
This is similar to defining your tasks in a for loop, but instead of having the DAG file fetch the data and do that itself, the scheduler can do this based on the output of a previous task. Unlike a Python for-loop executed at DAG parse time, dynamic task mapping defers task creation until runtime, allowing the scheduler to determine the exact number of task instances based on upstream task outputs. Right before a mapped task is executed the scheduler will create n copies of the task, one for each input.
It is also possible to have a task operate on the collected output of a mapped task, commonly known as map and reduce.
Simple mapping
In its simplest form you can map over a list defined directly in your Dag file using the expand() function instead of calling your task directly.
If you want to see a simple usage of Dynamic Task Mapping, you can look below:
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
"""Example DAG demonstrating the usage of dynamic task mapping."""
from __future__ import annotations
from datetime import datetime
from airflow.sdk import DAG, task, task_group
with DAG(
dag_id="example_dynamic_task_mapping", schedule=None, start_date=datetime(2022, 3, 4), tags=["example"]
):
@task
def add_one(x: int):
return x + 1
@task
def sum_it(values):
total = sum(values)
print(f"Total was {total}")
added_values = add_one.expand(x=[1, 2, 3])
sum_it(added_values)
with DAG(
dag_id="example_task_mapping_second_order",
schedule=None,
catchup=False,
start_date=datetime(2022, 3, 4),
tags=["example"],
):
@task
def get_nums():
return [1, 2, 3]
@task
def times_2(num):
return num * 2
@task
def add_10(num):
return num + 10
_get_nums = get_nums()
_times_2 = times_2.expand(num=_get_nums)
add_10.expand(num=_times_2)
with DAG(
dag_id="example_task_group_mapping",
schedule=None,
catchup=False,
start_date=datetime(2022, 3, 4),
tags=["example"],
):
@task_group
def op(num):
@task
def add_1(num):
return num + 1
@task
def mul_2(num):
return num * 2
return mul_2(add_1(num))
op.expand(num=[1, 2, 3])
This will show Total was 9 in the task logs when executed.
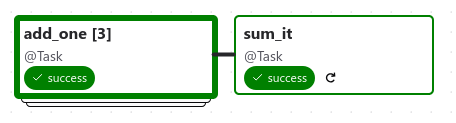
This is the resulting Dag structure:
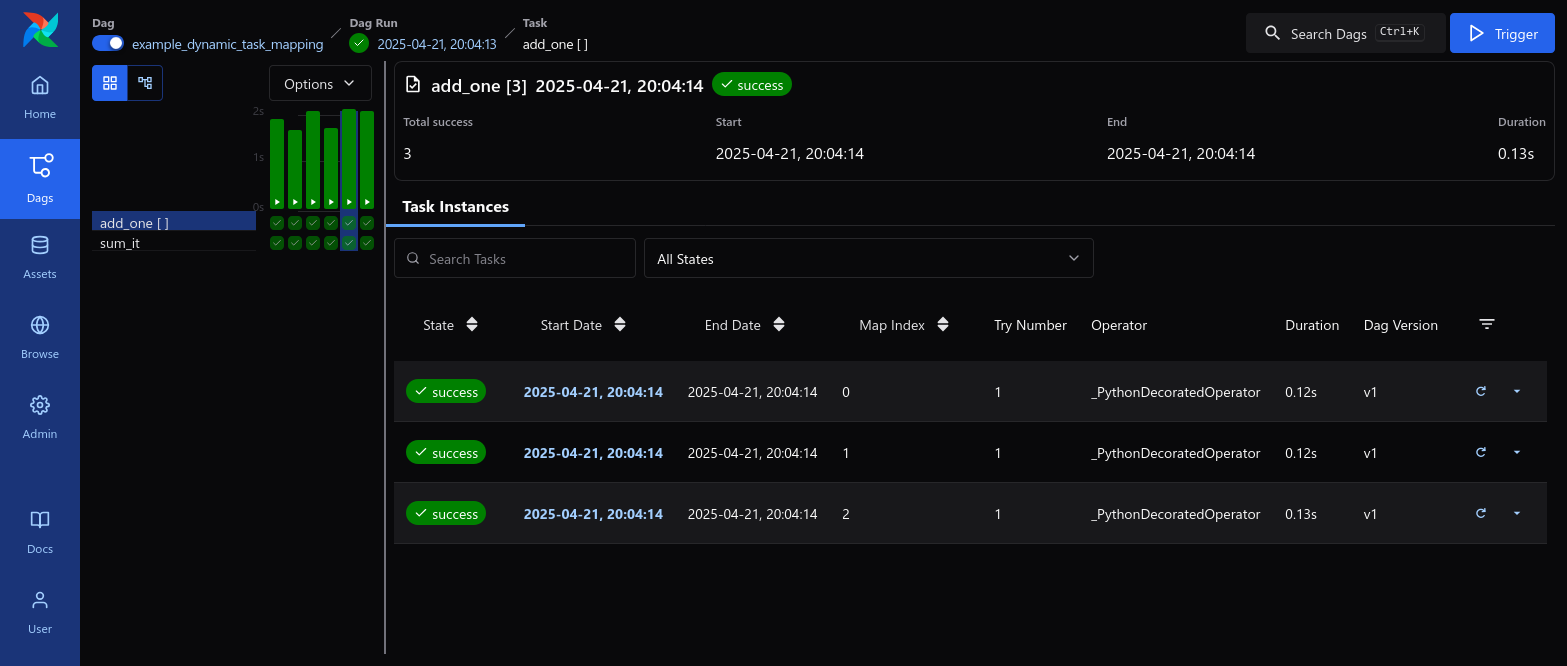
The grid view also provides visibility into your mapped tasks in the details panel:
Note
Only keyword arguments are allowed to be passed to expand().
Note
Values passed from the mapped task is a lazy proxy
In the above example, values received by sum_it is an aggregation of all values returned by each mapped instance of add_one. However, since it is impossible to know how many instances of add_one we will have in advance, values is not a normal list, but a “lazy sequence” that retrieves each individual value only when asked. Therefore, if you run print(values) directly, you would get something like this:
LazySelectSequence([15 items])
You can use normal sequence syntax on this object (e.g. values[0]), or iterate through it normally with a for loop. list(values) will give you a “real” list, but since this would eagerly load values from all of the referenced upstream mapped tasks, you must be aware of the potential performance implications if the mapped number is large.
Note that the same also applies to when you push this proxy object into XCom. Airflow tries to be smart and coerce the value automatically, but will emit a warning for this so you are aware of this. For example:
@task
def forward_values(values):
return values # This is a lazy proxy!
will emit a warning like this:
Coercing mapped lazy proxy return value from task forward_values to list, which may degrade
performance. Review resource requirements for this operation, and call list() explicitly to suppress this message. See Dynamic Task Mapping documentation for more information about lazy proxy objects.
The message can be suppressed by modifying the task like this:
@task
def forward_values(values):
return list(values)
Note
A reduce task is not required.
Although we show a “reduce” task here (sum_it) you don’t have to have one, the mapped tasks will still be executed even if they have no downstream tasks.
Task-generated Mapping
The above examples we’ve shown could all be achieved with a for loop in the Dag file, but the real power of dynamic task mapping comes from being able to have a task generate the list to iterate over.
@task
def make_list():
# This can also be from an API call, checking a database, -- almost anything you like, as long as the
# resulting list/dictionary can be stored in the current XCom backend.
return [1, 2, {"a": "b"}, "str"]
@task
def consumer(arg):
print(arg)
with DAG(dag_id="dynamic-map", start_date=datetime(2022, 4, 2)) as dag:
consumer.expand(arg=make_list())
The make_list task runs as a normal task and must return a list or dict (see What data types can be expanded?), and then the consumer task will be called four times, once with each value in the return of make_list.
Warning
Task-generated mapping cannot be utilized with TriggerRule.ALWAYS
Assigning trigger_rule=TriggerRule.ALWAYS in task-generated mapping is not allowed, as expanded parameters are undefined with the task’s immediate execution.
This is enforced at the time of the Dag parsing, for both tasks and mapped tasks groups, and will raise an error if you try to use it.
In the recent example, setting trigger_rule=TriggerRule.ALWAYS in the consumer task will raise an error since make_list is a task-generated mapping.
Repeated mapping
The result of one mapped task can also be used as input to the next mapped task.
with DAG(dag_id="repeated_mapping", start_date=datetime(2022, 3, 4)) as dag:
@task
def add_one(x: int):
return x + 1
first = add_one.expand(x=[1, 2, 3])
second = add_one.expand(x=first)
This would have a result of [3, 4, 5].
Adding parameters that do not expand
As well as passing arguments that get expanded at run-time, it is possible to pass arguments that don’t change—in order to clearly differentiate between the two kinds we use different functions, expand() for mapped arguments, and partial() for unmapped ones.
@task
def add(x: int, y: int):
return x + y
added_values = add.partial(y=10).expand(x=[1, 2, 3])
# This results in add function being expanded to
# add(x=1, y=10)
# add(x=2, y=10)
# add(x=3, y=10)
This would result in values of 11, 12, and 13.
This is also useful for passing things such as connection IDs, database table names, or bucket names to tasks.
Mapping over multiple parameters
As well as a single parameter it is possible to pass multiple parameters to expand. This will have the effect of creating a “cross product”, calling the mapped task with each combination of parameters.
@task
def add(x: int, y: int):
return x + y
added_values = add.expand(x=[2, 4, 8], y=[5, 10])
# This results in the add function being called with
# add(x=2, y=5)
# add(x=2, y=10)
# add(x=4, y=5)
# add(x=4, y=10)
# add(x=8, y=5)
# add(x=8, y=10)
This would result in the add task being called 6 times. Please note, however, that the order of expansion is not guaranteed.
Named mapping
By default, mapped tasks are assigned an integer index. It is possible to override the integer index for each mapped task in the Airflow UI with a name based on the task’s input. This is done by providing a Jinja template for the task with map_index_template. This will typically look like map_index_template="{{ task.<property> }}" when the expansion looks like .expand(<property>=...). This template is rendered after each expanded task is executed using the task context. This means you can reference attributes on the task like this:
from airflow.providers.common.sql.operators.sql import SQLExecuteQueryOperator
# The two expanded task instances will be named "2024-01-01" and "2024-01-02".
SQLExecuteQueryOperator.partial(
...,
sql="SELECT * FROM data WHERE date = %(date)s",
map_index_template="""{{ task.parameters['date'] }}""",
).expand(
parameters=[{"date": "2024-01-01"}, {"date": "2024-01-02"}],
)
In the above example, the expanded task instances will be named “2024-01-01” and “2024-01-02”. The names show up in the Airflow UI instead of “0” and “1”, respectively.
Since the template is rendered after the main execution block, it is possible to also dynamically inject into the rendering context. This is useful when the logic to render a desirable name is difficult to express in the Jinja template syntax, particularly in a taskflow function. For example:
from airflow.sdk import get_current_context
@task(map_index_template="{{ my_variable }}")
def my_task(my_value: str):
context = get_current_context()
context["my_variable"] = my_value * 3
... # Normal execution...
# The task instances will be named "aaa" and "bbb".
my_task.expand(my_value=["a", "b"])
Mapping with non-TaskFlow operators
It is possible to use partial and expand with classic style operators as well. Some arguments are not mappable and must be passed to partial(), such as task_id, queue, pool, and most other arguments to BaseOperator.
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
"""Example DAG demonstrating the usage of dynamic task mapping with non-TaskFlow operators."""
from __future__ import annotations
from datetime import datetime
from airflow.sdk import DAG, BaseOperator
class AddOneOperator(BaseOperator):
"""A custom operator that adds one to the input."""
def __init__(self, value, **kwargs):
super().__init__(**kwargs)
self.value = value
def execute(self, context):
return self.value + 1
class SumItOperator(BaseOperator):
"""A custom operator that sums the input."""
template_fields = ("values",)
def __init__(self, values, **kwargs):
super().__init__(**kwargs)
self.values = values
def execute(self, context):
total = sum(self.values)
print(f"Total was {total}")
return total
with DAG(
dag_id="example_dynamic_task_mapping_with_no_taskflow_operators",
schedule=None,
start_date=datetime(2022, 3, 4),
catchup=False,
tags=["example"],
):
# map the task to a list of values
add_one_task = AddOneOperator.partial(task_id="add_one").expand(value=[1, 2, 3])
# aggregate (reduce) the mapped tasks results
sum_it_task = SumItOperator(task_id="sum_it", values=add_one_task.output)
Note
Only keyword arguments are allowed to be passed to partial().
Mapping over result of classic operators
If you want to map over the result of a classic operator, you should explicitly reference the output, instead of the operator itself.
# Create a list of data inputs.
extract = ExtractOperator(task_id="extract")
# Expand the operator to transform each input.
transform = TransformOperator.partial(task_id="transform").expand(input=extract.output)
# Collect the transformed inputs, expand the operator to load each one of them to the target.
load = LoadOperator.partial(task_id="load").expand(input=transform.output)
Mixing TaskFlow and classic operators
In this example, you have a regular data delivery to an S3 bucket and want to apply the same processing to every file that arrives, no matter how many arrive each time.
from datetime import datetime
from airflow.sdk import DAG
from airflow.sdk import task
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
from airflow.providers.amazon.aws.operators.s3 import S3ListOperator
with DAG(dag_id="mapped_s3", start_date=datetime(2020, 4, 7)) as dag:
list_filenames = S3ListOperator(
task_id="get_input",
bucket="example-bucket",
prefix='incoming/provider_a/{{ data_interval_start.strftime("%Y-%m-%d") }}',
)
@task
def count_lines(aws_conn_id, bucket, filename):
hook = S3Hook(aws_conn_id=aws_conn_id)
return len(hook.read_key(filename, bucket).splitlines())
@task
def total(lines):
return sum(lines)
counts = count_lines.partial(aws_conn_id="aws_default", bucket=list_filenames.bucket).expand(
filename=list_filenames.output
)
total(lines=counts)
Assigning multiple parameters to a non-TaskFlow operator
Sometimes an upstream needs to specify multiple arguments to a downstream operator. To do this, you can use the expand_kwargs function, which takes a sequence of mappings to map against.
BashOperator.partial(task_id="bash").expand_kwargs(
[
{"bash_command": "echo $ENV1", "env": {"ENV1": "1"}},
{"bash_command": "printf $ENV2", "env": {"ENV2": "2"}},
],
)
This produces two task instances at run-time printing 1 and 2 respectively.
Also it’s possible to mix expand_kwargs with most of the operators arguments like the op_kwargs of the PythonOperator
def print_args(x, y):
print(x)
print(y)
return x + y
PythonOperator.partial(task_id="task-1", python_callable=print_args).expand_kwargs(
[
{"op_kwargs": {"x": 1, "y": 2}, "show_return_value_in_logs": True},
{"op_kwargs": {"x": 3, "y": 4}, "show_return_value_in_logs": False},
]
)
Similar to expand, you can also map against a XCom that returns a list of dicts, or a list of XComs each returning a dict. Reusing the S3 example above, you can use a mapped task to perform “branching” and copy files to different buckets:
list_filenames = S3ListOperator(...) # Same as the above example.
@task
def create_copy_kwargs(filename):
if filename.rsplit(".", 1)[-1] not in ("json", "yml"):
dest_bucket_name = "my_text_bucket"
else:
dest_bucket_name = "my_other_bucket"
return {
"source_bucket_key": filename,
"dest_bucket_key": filename,
"dest_bucket_name": dest_bucket_name,
}
copy_kwargs = create_copy_kwargs.expand(filename=list_filenames.output)
# Copy files to another bucket, based on the file's extension.
copy_filenames = S3CopyObjectOperator.partial(
task_id="copy_files", source_bucket_name=list_filenames.bucket
).expand_kwargs(copy_kwargs)
Mapping over a task group
Similar to a TaskFlow task, you can also call either expand or expand_kwargs on a @task_group-decorated function to create a mapped task group:
Note
Implementations of individual tasks in this section are omitted for brevity.
@task_group
def file_transforms(filename):
return convert_to_yaml(filename)
file_transforms.expand(filename=["data1.json", "data2.json"])
In the above example, task convert_to_yaml is expanded into two task instances at runtime. The first expanded would receive "data1.json" as input, and the second "data2.json".
Value references in a task group function
One important distinction between a task function (@task) and a task group function (@task_group) is, since a task group does not have an associated worker, code in a task group function cannot resolve arguments passed into it; the real value and is only resolved when the reference is passed into a task.
For example, this code will not work:
@task def my_task(value): print(value) @task_group def my_task_group(value): if not value: # DOES NOT work as you'd expect! task_a = EmptyOperator(...) else: task_a = PythonOperator(...) task_a << my_task(value) my_task_group.expand(value=[0, 1, 2])
When code in my_task_group is executed, value would still only be a reference, not the real value, so the if not value branch will not work as you likely want. However, if you pass that reference into a task, it will become resolved when the task is executed, and the three my_task instances will therefore receive 1, 2, and 3, respectively.
It is, therefore, important to remember that, if you intend to perform any logic to a value passed into a task group function, you must always use a task to run the logic, such as @task.branch (or BranchPythonOperator) for conditions, and task mapping methods for loops.
Note
Task-mapping in a mapped task group is not permitted
It is not currently permitted to do task mapping nested inside a mapped task group. While the technical aspect of this feature is not particularly difficult, we have decided to intentionally omit this feature since it adds considerable UI complexities, and may not be necessary for general use cases. This restriction may be revisited in the future depending on user feedback.
Depth-first execution
If a mapped task group contains multiple tasks, all tasks in the group are expanded “together” against the same inputs. For example:
@task_group
def file_transforms(filename):
converted = convert_to_yaml(filename)
return replace_defaults(converted)
file_transforms.expand(filename=["data1.json", "data2.json"])
Since the group file_transforms is expanded into two, tasks convert_to_yaml and replace_defaults will each become two instances at runtime.
A similar effect can be achieved by expanding the two tasks separately like so:
converted = convert_to_yaml.expand(filename=["data1.json", "data2.json"])
replace_defaults.expand(filename=converted)
The difference, however, is that a task group allows each task inside to only depend on its “relevant inputs”. For the above example, the replace_defaults would only depend on convert_to_yaml of the same expanded group, not instances of the same task, but in a different group. This strategy, called depth-first execution (in contrast to the simple group-less breath-first execution), allows for more logical task separation, fine-grained dependency rules, and accurate resource allocation—using the above example, the first replace_defaults would be able to run before convert_to_yaml("data2.json") is done, and does not need to care about whether it succeeds or not.
Depending on a mapped task group’s output
Similar to a mapped task group, depending on a mapped task group’s output would also automatically aggregate the group’s results:
@task_group
def add_to(value):
value = add_one(value)
return double(value)
results = add_to.expand(value=[1, 2, 3])
consumer(results) # Will receive [4, 6, 8].
It is also possible to perform any operations as results from a normal mapped task.
Branching on a mapped task group’s output
While it’s not possible to implement branching logic (for example using @task.branch) on the results of a mapped task, it is possible to branch based on the input of a task group. The following example demonstrates executing one of three tasks based on the input to a mapped task group.
inputs = ["a", "b", "c"]
@task_group(group_id="my_task_group")
def my_task_group(input):
@task.branch
def branch(element):
if "a" in element:
return "my_task_group.a"
elif "b" in element:
return "my_task_group.b"
else:
return "my_task_group.c"
@task
def a():
print("a")
@task
def b():
print("b")
@task
def c():
print("c")
branch(input) >> [a(), b(), c()]
my_task_group.expand(input=inputs)
Filtering items from a mapped task
A mapped task can remove any elements from being passed on to its downstream tasks by returning None. For example, if we want to only copy files from an S3 bucket to another with certain extensions, we could implement create_copy_kwargs like this instead:
@task
def create_copy_kwargs(filename):
# Skip files not ending with these suffixes.
if filename.rsplit(".", 1)[-1] not in ("json", "yml"):
return None
return {
"source_bucket_key": filename,
"dest_bucket_key": filename,
"dest_bucket_name": "my_other_bucket",
}
# copy_kwargs and copy_files are implemented the same.
This makes copy_files only expand against .json and .yml files, while ignoring the rest.
Transforming expanding data
Since it is common to want to transform the output data format for task mapping, especially from a non-TaskFlow operator, where the output format is pre-determined and cannot be easily converted (such as create_copy_kwargs in the above example), a special map() function can be used to easily perform this kind of transformation. The above example can therefore be modified like this:
from airflow.exceptions import AirflowSkipException
list_filenames = S3ListOperator(...) # Unchanged.
def create_copy_kwargs(filename):
if filename.rsplit(".", 1)[-1] not in ("json", "yml"):
raise AirflowSkipException(f"skipping {filename!r}; unexpected suffix")
return {
"source_bucket_key": filename,
"dest_bucket_key": filename,
"dest_bucket_name": "my_other_bucket",
}
copy_kwargs = list_filenames.output.map(create_copy_kwargs)
# Unchanged.
copy_filenames = S3CopyObjectOperator.partial(...).expand_kwargs(copy_kwargs)
There are a couple of things to note:
The callable argument of
map()(create_copy_kwargsin the example) must not be a task, but a plain Python function. The transformation is as a part of the “pre-processing” of the downstream task (i.e.copy_files), not a standalone task in the Dag.The callable always take exactly one positional argument. This function is called for each item in the iterable used for task-mapping, similar to how Python’s built-in
map()works.Since the callable is executed as a part of the downstream task, you can use any existing techniques to write the task function. To mark a component as skipped, for example, you should raise
AirflowSkipException. Note that returningNonedoes not work here.
Combining upstream data (aka “zipping”)
It is also common to want to combine multiple input sources into one task mapping iterable. This is generally known as “zipping” (like Python’s built-in zip() function), and is also performed as pre-processing of the downstream task.
This is especially useful for conditional logic in task mapping. For example, if you want to download files from S3, but rename those files, something like this would be possible:
list_filenames_a = S3ListOperator(
task_id="list_files_in_a",
bucket="bucket",
prefix="incoming/provider_a/{{ data_interval_start|ds }}",
)
list_filenames_b = ["rename_1", "rename_2", "rename_3", ...]
filenames_a_b = list_filenames_a.output.zip(list_filenames_b)
@task
def download_filea_from_a_rename(filenames_a_b):
fn_a, fn_b = filenames_a_b
S3Hook().download_file(fn_a, local_path=fn_b)
download_filea_from_a_rename.expand(filenames_a_b=filenames_a_b)
Similar to the built-in zip(), you can zip an arbitrary number of iterables together to get an iterable of tuples of the positional arguments’ count. By default, the zipped iterable’s length is the same as the shortest of the zipped iterables, with superfluous items dropped. An optional keyword argument default can be passed to switch the behavior to match Python’s itertools.zip_longest()—the zipped iterable will have the same length as the longest of the zipped iterables, with missing items filled with the value provided by default.
Concatenating multiple upstreams
Another common pattern to combine input sources is to run the same task against multiple iterables. It is of course totally valid to simply run the same code separately for each iterable, for example:
list_filenames_a = S3ListOperator(
task_id="list_files_in_a",
bucket="bucket",
prefix="incoming/provider_a/{{ data_interval_start|ds }}",
)
list_filenames_b = S3ListOperator(
task_id="list_files_in_b",
bucket="bucket",
prefix="incoming/provider_b/{{ data_interval_start|ds }}",
)
@task
def download_file(filename):
S3Hook().download_file(filename)
# process file...
download_file.override(task_id="download_file_a").expand(filename=list_filenames_a.output)
download_file.override(task_id="download_file_b").expand(filename=list_filenames_b.output)
The Dag, however, would be both more scalable and easier to inspect if the tasks can be combined into one. This can done with concat:
# Tasks list_filenames_a and list_filenames_b, and download_file stay unchanged.
list_filenames_concat = list_filenames_a.concat(list_filenames_b)
download_file.expand(filename=list_filenames_concat)
This creates one single task to expand against both lists instead. You can concat an arbitrary number of iterables together (e.g. foo.concat(bar, rex)); alternatively, since the return value is also an XCom reference, the concat calls can be chained (e.g. foo.concat(bar).concat(rex)) to achieve the same result: one single iterable that concatenates all of them in order, similar to Python’s itertools.chain().
What data types can be expanded?
Currently it is only possible to map against a dict, a list, or one of those types stored in XCom as the result of a task.
If an upstream task returns an unmappable type, the mapped task will fail at run-time with an UnmappableXComTypePushed exception. For instance, you can’t have the upstream task return a plain string – it must be a list or a dict.
How do templated fields and mapped arguments interact?
All arguments to an operator can be mapped, even those that do not accept templated parameters.
If a field is marked as being templated and is mapped, it will not be templated.
For example, this will print {{ ds }} and not a date stamp:
@task
def make_list():
return ["{{ ds }}"]
@task
def printer(val):
print(val)
printer.expand(val=make_list())
If you want to interpolate values either call task.render_template yourself, or use interpolation:
@task
def make_list(ds=None):
return [ds]
@task
def make_list(**context):
return [context["task"].render_template("{{ ds }}", context)]
Placing limits on mapped tasks
There are two limits that you can place on a task:
the number of mapped task instances can be created as the result of expansion.
The number of the mapped task can run at once.
Limiting number of mapped task
The [core]
max_map_lengthconfig option is the maximum number of tasks thatexpandcan create – the default value is 1024.If a source task (
make_listin our earlier example) returns a list longer than this it will result in that task failing.Limiting parallel copies of a mapped task
If you wish to not have a large mapped task consume all available runner slots you can use the
max_active_tis_per_dagsetting on the task to restrict how many can be running at the same time.Note, however, that this applies to all copies of that task against all active DagRuns, not just to this one specific DagRun.
@task(max_active_tis_per_dag=16) def add_one(x: int): return x + 1 BashOperator.partial(task_id="my_task", max_active_tis_per_dag=16).expand(bash_command=commands)
Automatically skipping zero-length maps
If the input is empty (zero length), no new tasks will be created and the mapped task will be marked as SKIPPED.
This can be useful when a Dag discovers work to do at runtime, but sometimes there is no work for that run. For example, a scan-and-repair Dag can return an empty list when it does not find anything to repair. In that case, the mapped task is skipped, and a downstream summary task can still treat the run as a successful no-op if it uses a trigger rule that allows skipped upstream tasks.
from airflow.sdk import TriggerRule, task
@task
def find_work_items():
# Return an empty list when no files, records, or partitions need repair.
return []
@task
def repair(item): ...
@task(trigger_rule=TriggerRule.NONE_FAILED)
def summarize(repaired_items):
if not repaired_items:
print("No work found; nothing to repair.")
return
print(f"Repaired {len(repaired_items)} item(s).")
repaired_items = repair.expand(item=find_work_items())
summarize(repaired_items)