Quick Start¶
Note
On November 2020, new version of PIP (20.3) has been released with a new, 2020 resolver. This resolver
does not yet work with Apache Airflow and might leads to errors in installation - depends on your choice
of extras. In order to install Airflow you need to either downgrade pip to version 20.2.4
pip upgrade --pip==20.2.4 or, in case you use Pip 20.3, you need to add option
--use-deprecated legacy-resolver to your pip install command.
The installation is quick and straightforward.
# airflow needs a home, ~/airflow is the default,
# but you can lay foundation somewhere else if you prefer
# (optional)
export AIRFLOW_HOME=~/airflow
# install from pypi using pip
pip install apache-airflow
# initialize the database
airflow db init
airflow users create \
--username admin \
--firstname Peter \
--lastname Parker \
--role Admin \
--email spiderman@superhero.org
# start the web server, default port is 8080
airflow webserver --port 8080
# start the scheduler
# open a new terminal or else run webserver with ``-D`` option to run it as a daemon
airflow scheduler
# visit localhost:8080 in the browser and use the admin account you just
# created to login. Enable the example_bash_operator dag in the home page
Upon running these commands, Airflow will create the $AIRFLOW_HOME folder
and create the "airflow.cfg" file with defaults that will get you going fast.
You can inspect the file either in $AIRFLOW_HOME/airflow.cfg, or through the UI in
the Admin->Configuration menu. The PID file for the webserver will be stored
in $AIRFLOW_HOME/airflow-webserver.pid or in /run/airflow/webserver.pid
if started by systemd.
Out of the box, Airflow uses a sqlite database, which you should outgrow
fairly quickly since no parallelization is possible using this database
backend. It works in conjunction with the airflow.executors.sequential_executor.SequentialExecutor which will
only run task instances sequentially. While this is very limiting, it allows
you to get up and running quickly and take a tour of the UI and the
command line utilities.
Here are a few commands that will trigger a few task instances. You should
be able to see the status of the jobs change in the example_bash_operator DAG as you
run the commands below.
# run your first task instance
airflow tasks run example_bash_operator runme_0 2015-01-01
# run a backfill over 2 days
airflow dags backfill example_bash_operator \
--start-date 2015-01-01 \
--end-date 2015-01-02
Basic Airflow architecture¶
Primarily intended for development use, the basic Airflow architecture with the Local and Sequential executors is an excellent starting point for understanding the architecture of Apache Airflow.
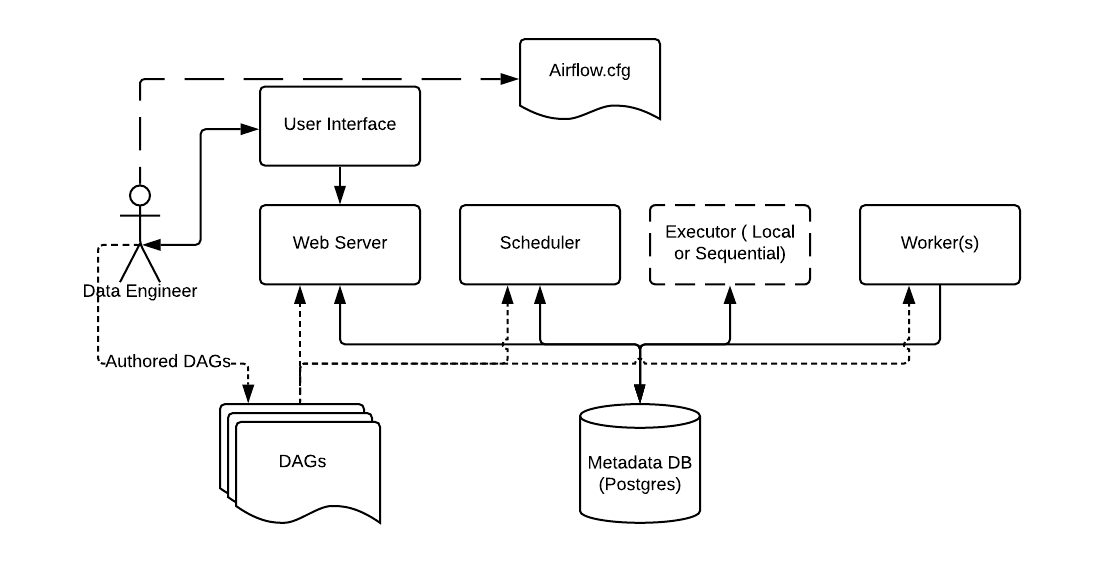
There are a few components to note:
Metadata Database: Airflow uses a SQL database to store metadata about the data pipelines being run. In the diagram above, this is represented as Postgres which is extremely popular with Airflow. Alternate databases supported with Airflow include MySQL.
Web Server and Scheduler: The Airflow web server and Scheduler are separate processes run (in this case) on the local machine and interact with the database mentioned above.
The Executor is shown separately above, since it is commonly discussed within Airflow and in the documentation, but in reality it is NOT a separate process, but run within the Scheduler.
The Worker(s) are separate processes which also interact with the other components of the Airflow architecture and the metadata repository.
airflow.cfgis the Airflow configuration file which is accessed by the Web Server, Scheduler, and Workers.DAGs refers to the DAG files containing Python code, representing the data pipelines to be run by Airflow. The location of these files is specified in the Airflow configuration file, but they need to be accessible by the Web Server, Scheduler, and Workers.
What's Next?¶
From this point, you can head to the Tutorial section for further examples or the How-to Guides section if you're ready to get your hands dirty.