Best Practices¶
Creating a new DAG is a two-step process:
writing Python code to create a DAG object,
testing if the code meets our expectations
This tutorial will introduce you to the best practices for these two steps.
Writing a DAG¶
Creating a new DAG in Airflow is quite simple. However, there are many things that you need to take care of to ensure the DAG run or failure does not produce unexpected results.
Creating a Custom Operator/Hook¶
Please follow our guide on custom Operators.
Creating a task¶
You should treat tasks in Airflow equivalent to transactions in a database. This
implies that you should never produce incomplete results from your tasks. An
example is not to produce incomplete data in HDFS or S3 at the end of a
task.
Airflow can retry a task if it fails. Thus, the tasks should produce the same outcome on every re-run. Some of the ways you can avoid producing a different result -
Do not use INSERT during a task re-run, an INSERT statement might lead to duplicate rows in your database. Replace it with UPSERT.
Read and write in a specific partition. Never read the latest available data in a task. Someone may update the input data between re-runs, which results in different outputs. A better way is to read the input data from a specific partition. You can use
data_interval_startas a partition. You should follow this partitioning method while writing data in S3/HDFS as well.The Python datetime
now()function gives the current datetime object. This function should never be used inside a task, especially to do the critical computation, as it leads to different outcomes on each run. It’s fine to use it, for example, to generate a temporary log.
Tip
You should define repetitive parameters such as connection_id or S3 paths in default_args rather than declaring them for each task.
The default_args help to avoid mistakes such as typographical errors. Also, most connection types have unique parameter names in
tasks, so you can declare a connection only once in default_args (for example gcp_conn_id) and it is automatically
used by all operators that use this connection type.
Deleting a task¶
Be careful when deleting a task from a DAG. You would not be able to see the Task in Graph View, Tree View, etc making it difficult to check the logs of that Task from the Webserver. If that is not desired, please create a new DAG.
Communication¶
Airflow executes tasks of a DAG on different servers in case you are using Kubernetes executor or Celery executor.
Therefore, you should not store any file or config in the local filesystem as the next task is likely to run on a different server without access to it — for example, a task that downloads the data file that the next task processes.
In the case of Local executor,
storing a file on disk can make retries harder e.g., your task requires a config file that is deleted by another task in DAG.
If possible, use XCom to communicate small messages between tasks and a good way of passing larger data between tasks is to use a remote storage such as S3/HDFS.
For example, if we have a task that stores processed data in S3 that task can push the S3 path for the output data in Xcom,
and the downstream tasks can pull the path from XCom and use it to read the data.
The tasks should also not store any authentication parameters such as passwords or token inside them. Where at all possible, use Connections to store data securely in Airflow backend and retrieve them using a unique connection id.
Top level Python Code¶
You should avoid writing the top level code which is not necessary to create Operators and build DAG relations between them. This is because of the design decision for the scheduler of Airflow and the impact the top-level code parsing speed on both performance and scalability of Airflow.
Airflow scheduler executes the code outside the Operator’s execute methods with the minimum interval of
min_file_process_interval seconds. This is done in order
to allow dynamic scheduling of the DAGs - where scheduling and dependencies might change over time and
impact the next schedule of the DAG. Airflow scheduler tries to continuously make sure that what you have
in DAGs is correctly reflected in scheduled tasks.
Specifically you should not run any database access, heavy computations and networking operations.
One of the important factors impacting DAG loading time, that might be overlooked by Python developers is that top-level imports might take surprisingly a lot of time and they can generate a lot of overhead and this can be easily avoided by converting them to local imports inside Python callables for example.
Consider the example below - the first DAG will parse significantly slower (in the orders of seconds)
than equivalent DAG where the numpy module is imported as local import in the callable.
Bad example:
import pendulum
from airflow import DAG
from airflow.operators.python import PythonOperator
import numpy as np # <-- THIS IS A VERY BAD IDEA! DON'T DO THAT!
with DAG(
dag_id="example_python_operator",
schedule_interval=None,
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
tags=["example"],
) as dag:
def print_array():
"""Print Numpy array."""
a = np.arange(15).reshape(3, 5)
print(a)
return a
run_this = PythonOperator(
task_id="print_the_context",
python_callable=print_array,
)
Good example:
import pendulum
from airflow import DAG
from airflow.operators.python import PythonOperator
with DAG(
dag_id="example_python_operator",
schedule_interval=None,
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
tags=["example"],
) as dag:
def print_array():
"""Print Numpy array."""
import numpy as np # <- THIS IS HOW NUMPY SHOULD BE IMPORTED IN THIS CASE
a = np.arange(15).reshape(3, 5)
print(a)
return a
run_this = PythonOperator(
task_id="print_the_context",
python_callable=print_array,
)
Dynamic DAG Generation¶
Sometimes writing DAGs manually isn’t practical. Maybe you have a lot of DAGs that do similar things with just a parameter changing between them. Or maybe you need a set of DAGs to load tables, but don’t want to manually update DAGs every time those tables change. In these and other cases, it can be more useful to dynamically generate DAGs.
Avoiding excessive processing at the top level code described in the previous chapter is especially important in case of dynamic DAG configuration, which can be configured essentially in one of those ways:
via environment variables (not to be mistaken with the Airflow Variables)
via externally provided, generated Python code, containing meta-data in the DAG folder
via externally provided, generated configuration meta-data file in the DAG folder
Some cases of dynamic DAG generation are described in the Dynamic DAG Generation section.
Airflow Variables¶
As mentioned in the previous chapter, Top level Python Code. you should avoid
using Airflow Variables at top level Python code of DAGs. You can use the Airflow Variables freely inside the
execute() methods of the operators, but you can also pass the Airflow Variables to the existing operators
via Jinja template, which will delay reading the value until the task execution.
The template syntax to do this is:
{{ var.value.<variable_name> }}
or if you need to deserialize a json object from the variable :
{{ var.json.<variable_name> }}
For security purpose, you’re recommended to use the Secrets Backend for any variable that contains sensitive data.
Triggering DAGs after changes¶
Avoid triggering DAGs immediately after changing them or any other accompanying files that you change in the DAG folder.
You should give the system sufficient time to process the changed files. This takes several steps. First the files have to be distributed to scheduler - usually via distributed filesystem or Git-Sync, then scheduler has to parse the Python files and store them in the database. Depending on your configuration, speed of your distributed filesystem, number of files, number of DAGs, number of changes in the files, sizes of the files, number of schedulers, speed of CPUS, this can take from seconds to minutes, in extreme cases many minutes. You should wait for your DAG to appear in the UI to be able to trigger it.
In case you see long delays between updating it and the time it is ready to be triggered, you can look at the following configuration parameters and fine tune them according your needs (see details of each parameter by following the links):
Example of watcher pattern with trigger rules¶
The watcher pattern is how we call a DAG with a task that is “watching” the states of the other tasks. It’s primary purpose is to fail a DAG Run when any other task fail. The need came from the Airflow system tests that are DAGs with different tasks (similarly like a test containing steps).
Normally, when any task fails, all other tasks are not executed and the whole DAG Run gets failed status too. But
when we use trigger rules, we can disrupt the normal flow of running tasks and the whole DAG may represent different
status that we expect. For example, we can have a teardown task (with trigger rule set to TriggerRule.ALL_DONE)
that will be executed regardless of the state of the other tasks (e.g. to clean up the resources). In such
situation, the DAG would always run this task and the DAG Run will get the status of this particular task, so we can
potentially lose the information about failing tasks. If we want to ensure that the DAG with teardown task would fail
if any task fails, we need to use the watcher pattern. The watcher task is a task that will always fail if
triggered, but it needs to be triggered only if any other task fails. It needs to have a trigger rule set to
TriggerRule.ONE_FAILED and it needs also to be a downstream task for all other tasks in the DAG. Thanks to
this, if every other task will pass, the watcher will be skipped, but when something fails, the watcher task will be
executed and fail making the DAG Run fail too.
Note
Be aware that trigger rules only rely on the direct upstream (parent) tasks, e.g. TriggerRule.ONE_FAILED
will ignore any failed (or upstream_failed) tasks that are not a direct parent of the parameterized task.
It’s easier to grab the concept with an example. Let’s say that we have the following DAG:
from datetime import datetime
from airflow import DAG
from airflow.decorators import task
from airflow.exceptions import AirflowException
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
from airflow.utils.trigger_rule import TriggerRule
@task(trigger_rule=TriggerRule.ONE_FAILED, retries=0)
def watcher():
raise AirflowException("Failing task because one or more upstream tasks failed.")
with DAG(
dag_id="watcher_example",
schedule_interval="@once",
start_date=datetime(2021, 1, 1),
catchup=False,
) as dag:
failing_task = BashOperator(task_id="failing_task", bash_command="exit 1", retries=0)
passing_task = BashOperator(task_id="passing_task", bash_command="echo passing_task")
teardown = BashOperator(
task_id="teardown",
bash_command="echo teardown",
trigger_rule=TriggerRule.ALL_DONE,
)
failing_task >> passing_task >> teardown
list(dag.tasks) >> watcher()
The visual representation of this DAG after execution looks like this:
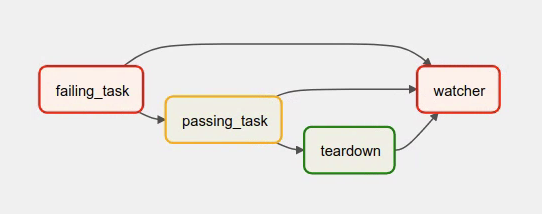
We have several tasks that serve different purposes:
failing_taskalways fails,passing_taskalways succeeds (if executed),teardownis always triggered (regardless the states of the other tasks) and it should always succeed,watcheris a downstream task for each other task, i.e. it will be triggered when any task fails and thus fail the whole DAG Run, since it’s a leaf task.
It’s important to note, that without watcher task, the whole DAG Run will get the success state, since the only failing task is not the leaf task, and the teardown task will finish with success.
If we want the watcher to monitor the state of all tasks, we need to make it dependent on all of them separately. Thanks to this, we can fail the DAG Run if any of the tasks fail. Note that the watcher task has a trigger rule set to "one_failed".
On the other hand, without the teardown task, the watcher task will not be needed, because failing_task will propagate its failed state to downstream task passed_task and the whole DAG Run will also get the failed status.
Reducing DAG complexity¶
While Airflow is good in handling a lot of DAGs with a lot of task and dependencies between them, when you have many complex DAGs, their complexity might impact performance of scheduling. One of the ways to keep your Airflow instance performant and well utilized, you should strive to simplify and optimize your DAGs whenever possible - you have to remember that DAG parsing process and creation is just executing Python code and it’s up to you to make it as performant as possible. There are no magic recipes for making your DAG “less complex” - since this is a Python code, it’s the DAG writer who controls the complexity of their code.
There are no “metrics” for DAG complexity, especially, there are no metrics that can tell you whether your DAG is “simple enough”. However - as with any Python code you can definitely tell that your code is “simpler” or “faster” when you optimize it, the same can be said about DAG code. If you want to optimize your DAGs there are the following actions you can take:
Make your DAG load faster. This is a single improvement advice that might be implemented in various ways but this is the one that has biggest impact on scheduler’s performance. Whenever you have a chance to make your DAG load faster - go for it, if your goal is to improve performance. Look at the Top level Python Code to get some tips of how you can do it. Also see at DAG Loader Test on how to asses your DAG loading time.
Make your DAG generate simpler structure. Every task dependency adds additional processing overhead for scheduling and execution. The DAG that has simple linear structure
A -> B -> Cwill experience less delays in task scheduling than DAG that has a deeply nested tree structure with exponentially growing number of depending tasks for example. If you can make your DAGs more linear - where at single point in execution there are as few potential candidates to run among the tasks, this will likely improve overall scheduling performance.Make smaller number of DAGs per file. While Airflow 2 is optimized for the case of having multiple DAGs in one file, there are some parts of the system that make it sometimes less performant, or introduce more delays than having those DAGs split among many files. Just the fact that one file can only be parsed by one FileProcessor, makes it less scalable for example. If you have many DAGs generated from one file, consider splitting them if you observe it takes a long time to reflect changes in your DAG files in the UI of Airflow.
Testing a DAG¶
Airflow users should treat DAGs as production level code, and DAGs should have various associated tests to ensure that they produce expected results. You can write a wide variety of tests for a DAG. Let’s take a look at some of them.
DAG Loader Test¶
This test should ensure that your DAG does not contain a piece of code that raises error while loading. No additional code needs to be written by the user to run this test.
python your-dag-file.py
Running the above command without any error ensures your DAG does not contain any uninstalled dependency, syntax errors, etc. Make sure that you load your DAG in an environment that corresponds to your scheduler environment - with the same dependencies, environment variables, common code referred from the DAG.
This is also a great way to check if your DAG loads faster after an optimization, if you want to attempt to optimize DAG loading time. Simply run the DAG and measure the time it takes, but again you have to make sure your DAG runs with the same dependencies, environment variables, common code.
There are many ways to measure the time of processing, one of them in Linux environment is to
use built-in time command. Make sure to run it several times in succession to account for
caching effects. Compare the results before and after the optimization (in the same conditions - using
the same machine, environment etc.) in order to assess the impact of the optimization.
time python airflow/example_dags/example_python_operator.py
Result:
real 0m0.699s
user 0m0.590s
sys 0m0.108s
The important metrics is the “real time” - which tells you how long time it took to process the DAG. Note that when loading the file this way, you are starting a new interpreter so there is an initial loading time that is not present when Airflow parses the DAG. You can assess the time of initialization by running:
time python -c ''
Result:
real 0m0.073s
user 0m0.037s
sys 0m0.039s
In this case the initial interpreter startup time is ~ 0.07s which is about 10% of time needed to parse the example_python_operator.py above so the actual parsing time is about ~ 0.62 s for the example DAG.
You can look into Testing a DAG for details on how to test individual operators.
Unit tests¶
Unit tests ensure that there is no incorrect code in your DAG. You can write unit tests for both your tasks and your DAG.
Unit test for loading a DAG:
import pytest
from airflow.models import DagBag
@pytest.fixture()
def dagbag():
return DagBag()
def test_dag_loaded(dagbag):
dag = dagbag.get_dag(dag_id="hello_world")
assert dagbag.import_errors == {}
assert dag is not None
assert len(dag.tasks) == 1
Unit test a DAG structure: This is an example test want to verify the structure of a code-generated DAG against a dict object
def assert_dag_dict_equal(source, dag):
assert dag.task_dict.keys() == source.keys()
for task_id, downstream_list in source.items():
assert dag.has_task(task_id)
task = dag.get_task(task_id)
assert task.downstream_task_ids == set(downstream_list)
def test_dag():
assert_dag_dict_equal(
{
"DummyInstruction_0": ["DummyInstruction_1"],
"DummyInstruction_1": ["DummyInstruction_2"],
"DummyInstruction_2": ["DummyInstruction_3"],
"DummyInstruction_3": [],
},
dag,
)
Unit test for custom operator:
import datetime
import pendulum
import pytest
from airflow.utils.state import DagRunState, TaskInstanceState
from airflow.utils.types import DagRunType
DATA_INTERVAL_START = pendulum.datetime(2021, 9, 13, tz="UTC")
DATA_INTERVAL_END = DATA_INTERVAL_START + datetime.timedelta(days=1)
TEST_DAG_ID = "my_custom_operator_dag"
TEST_TASK_ID = "my_custom_operator_task"
@pytest.fixture()
def dag():
with DAG(
dag_id=TEST_DAG_ID,
schedule_interval="@daily",
start_date=DATA_INTERVAL_START,
) as dag:
MyCustomOperator(
task_id=TEST_TASK_ID,
prefix="s3://bucket/some/prefix",
)
return dag
def test_my_custom_operator_execute_no_trigger(dag):
dagrun = dag.create_dagrun(
state=DagRunState.RUNNING,
execution_date=DATA_INTERVAL_START,
data_interval=(DATA_INTERVAL_START, DATA_INTERVAL_END),
start_date=DATA_INTERVAL_END,
run_type=DagRunType.MANUAL,
)
ti = dagrun.get_task_instance(task_id=TEST_TASK_ID)
ti.task = dag.get_task(task_id=TEST_TASK_ID)
ti.run(ignore_ti_state=True)
assert ti.state == TaskInstanceState.SUCCESS
# Assert something related to tasks results.
Self-Checks¶
You can also implement checks in a DAG to make sure the tasks are producing the results as expected. As an example, if you have a task that pushes data to S3, you can implement a check in the next task. For example, the check could make sure that the partition is created in S3 and perform some simple checks to determine if the data is correct.
Similarly, if you have a task that starts a microservice in Kubernetes or Mesos, you should check if the service has started or not using airflow.providers.http.sensors.http.HttpSensor.
task = PushToS3(...)
check = S3KeySensor(
task_id="check_parquet_exists",
bucket_key="s3://bucket/key/foo.parquet",
poke_interval=0,
timeout=0,
)
task >> check
Staging environment¶
If possible, keep a staging environment to test the complete DAG run before deploying in the production. Make sure your DAG is parameterized to change the variables, e.g., the output path of S3 operation or the database used to read the configuration. Do not hard code values inside the DAG and then change them manually according to the environment.
You can use environment variables to parameterize the DAG.
import os
dest = os.environ.get("MY_DAG_DEST_PATH", "s3://default-target/path/")
Mocking variables and connections¶
When you write tests for code that uses variables or a connection, you must ensure that they exist when you run the tests. The obvious solution is to save these objects to the database so they can be read while your code is executing. However, reading and writing objects to the database are burdened with additional time overhead. In order to speed up the test execution, it is worth simulating the existence of these objects without saving them to the database. For this, you can create environment variables with mocking os.environ using unittest.mock.patch.dict().
For variable, use AIRFLOW_VAR_{KEY}.
with mock.patch.dict("os.environ", AIRFLOW_VAR_KEY="env-value"):
assert "env-value" == Variable.get("key")
For connection, use AIRFLOW_CONN_{CONN_ID}.
conn = Connection(
conn_type="gcpssh",
login="cat",
host="conn-host",
)
conn_uri = conn.get_uri()
with mock.patch.dict("os.environ", AIRFLOW_CONN_MY_CONN=conn_uri):
assert "cat" == Connection.get("my_conn").login
Metadata DB maintenance¶
Over time, the metadata database will increase its storage footprint as more DAG and task runs and event logs accumulate.
You can use the Airflow CLI to purge old data with the command airflow db clean.
See db clean usage for more details.
Upgrades and downgrades¶
Backup your database¶
It’s always a wise idea to backup the metadata database before undertaking any operation modifying the database.
Disable the scheduler¶
You might consider disabling the Airflow cluster while you perform such maintenance.
One way to do so would be to set the param [scheduler] > use_job_schedule to False and wait for any running DAGs to complete; after this no new DAG runs will be created unless externally triggered.
A better way (though it’s a bit more manual) is to use the dags pause command. You’ll need to keep track of the DAGs that are paused before you begin this operation so that you know which ones to unpause after maintenance is complete. First run airflow dags list and store the list of unpaused DAGs. Then use this same list to run both dags pause for each DAG prior to maintenance, and dags unpause after. A benefit of this is you can try un-pausing just one or two DAGs (perhaps dedicated test dags) after the upgrade to make sure things are working before turning everything back on.
Add “integration test” DAGs¶
It can be helpful to add a couple “integration test” DAGs that use all the common services in your ecosystem (e.g. S3, Snowflake, Vault) but with dummy resources or “dev” accounts. These test DAGs can be the ones you turn on first after an upgrade, because if they fail, it doesn’t matter and you can revert to your backup without negative consequences. However, if they succeed, they should prove that your cluster is able to run tasks with the libraries and services that you need to use.
For example, if you use an external secrets backend, make sure you have a task that retrieves a connection. If you use KubernetesPodOperator, add a task that runs sleep 30; echo "hello". If you need to write to s3, do so in a test task. And if you need to access a database, add a task that does select 1 from the server.