DatabricksWorkflowTaskGroup¶
Use the DatabricksWorkflowTaskGroup to launch and monitor
Databricks notebook job runs as Airflow tasks. The task group launches a Databricks Workflow and runs the notebook jobs from within it.
There are a few advantages to defining your Databricks Workflows in Airflow:
Authoring interface |
via Databricks (Web-based with Databricks UI) |
via Airflow(Code with Airflow Dag) |
|---|---|---|
Workflow compute pricing |
✅ |
✅ |
Notebook code in source control |
✅ |
✅ |
Workflow structure in source control |
✅ |
✅ |
Retry from beginning |
✅ |
✅ |
Retry single task |
✅ |
✅ |
Task groups within Workflows |
✅ |
|
Trigger workflows from other Dags |
✅ |
|
Workflow-level parameters |
✅ |
Examples¶
Example of what a Dag looks like with a DatabricksWorkflowTaskGroup¶
task_group = DatabricksWorkflowTaskGroup(
group_id=f"test_workflow_{USER}_{GROUP_ID}",
databricks_conn_id=DATABRICKS_CONN_ID,
job_clusters=job_cluster_spec,
notebook_params={"ts": "{{ ts }}"},
notebook_packages=[
{
"pypi": {
"package": "simplejson==3.18.0", # Pin specification version of a package like this.
"repo": "https://pypi.org/simple", # You can specify your required Pypi index here.
}
},
],
extra_job_params={
"email_notifications": {
"on_start": [DATABRICKS_NOTIFICATION_EMAIL],
},
},
)
with task_group:
notebook_1 = DatabricksNotebookOperator(
task_id="workflow_notebook_1",
databricks_conn_id=DATABRICKS_CONN_ID,
notebook_path="/Shared/Notebook_1",
notebook_packages=[{"pypi": {"package": "Faker"}}],
source="WORKSPACE",
job_cluster_key="Shared_job_cluster",
execution_timeout=timedelta(seconds=600),
)
notebook_2 = DatabricksNotebookOperator(
task_id="workflow_notebook_2",
databricks_conn_id=DATABRICKS_CONN_ID,
notebook_path="/Shared/Notebook_2",
source="WORKSPACE",
job_cluster_key="Shared_job_cluster",
notebook_params={"foo": "bar", "ds": "{{ ds }}"},
)
task_operator_nb_1 = DatabricksTaskOperator(
task_id="nb_1",
databricks_conn_id=DATABRICKS_CONN_ID,
job_cluster_key="Shared_job_cluster",
task_config={
"notebook_task": {
"notebook_path": "/Shared/Notebook_1",
"source": "WORKSPACE",
},
"libraries": [
{"pypi": {"package": "Faker"}},
],
},
)
sql_query = DatabricksTaskOperator(
task_id="sql_query",
databricks_conn_id=DATABRICKS_CONN_ID,
task_config={
"sql_task": {
"query": {
"query_id": QUERY_ID,
},
"warehouse_id": WAREHOUSE_ID,
}
},
)
notebook_1 >> notebook_2 >> task_operator_nb_1 >> sql_query
With this example, Airflow will produce a job named <dag_name>.test_workflow_<USER>_<GROUP_ID> that will
run task notebook_1 and then notebook_2. The job will be created in the databricks workspace
if it does not already exist. If the job already exists, it will be updated to match
the workflow defined in the Dag.
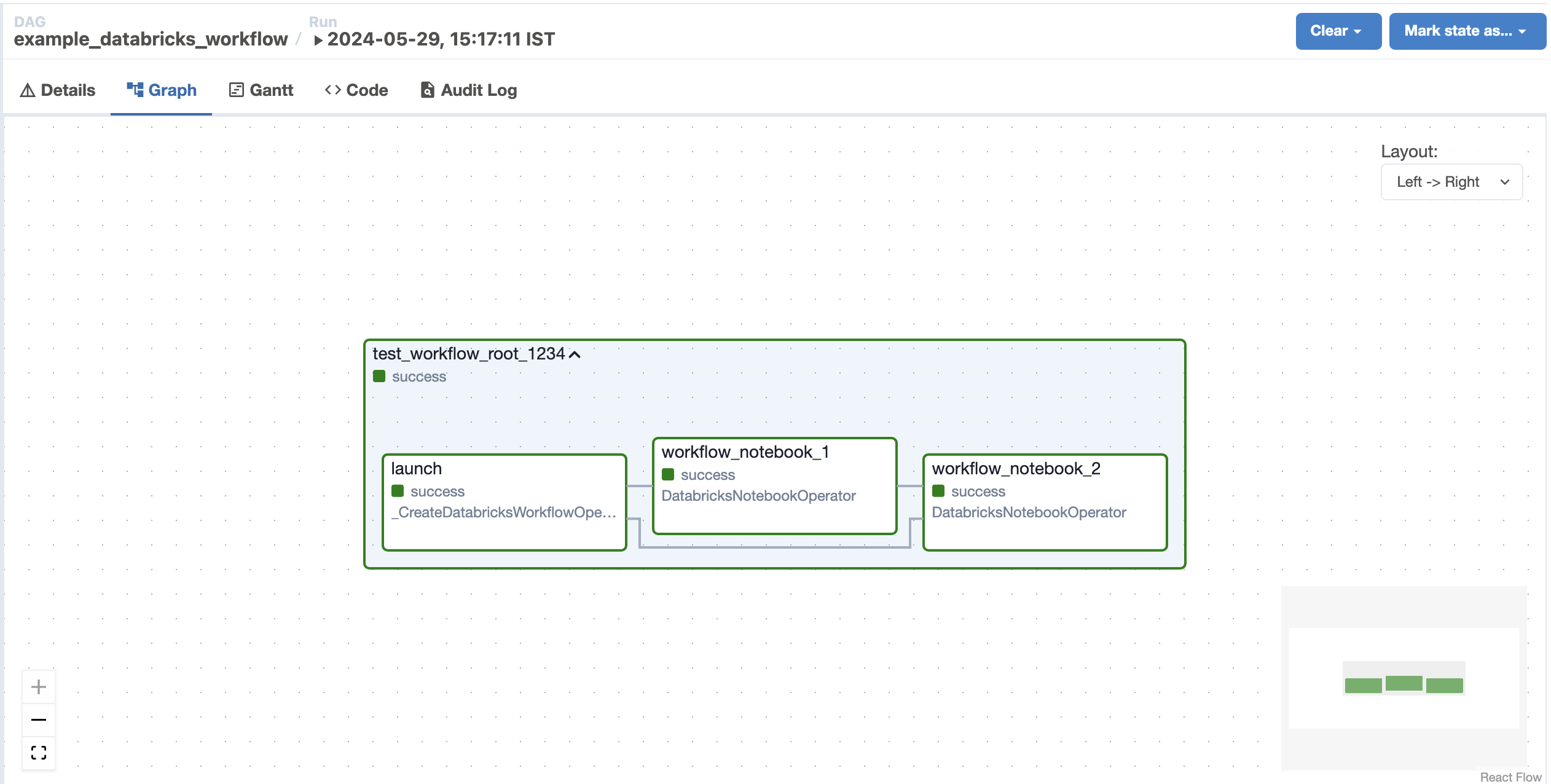
The following image displays the resulting Databricks Workflow in the Airflow UI (based on the above example provided)¶
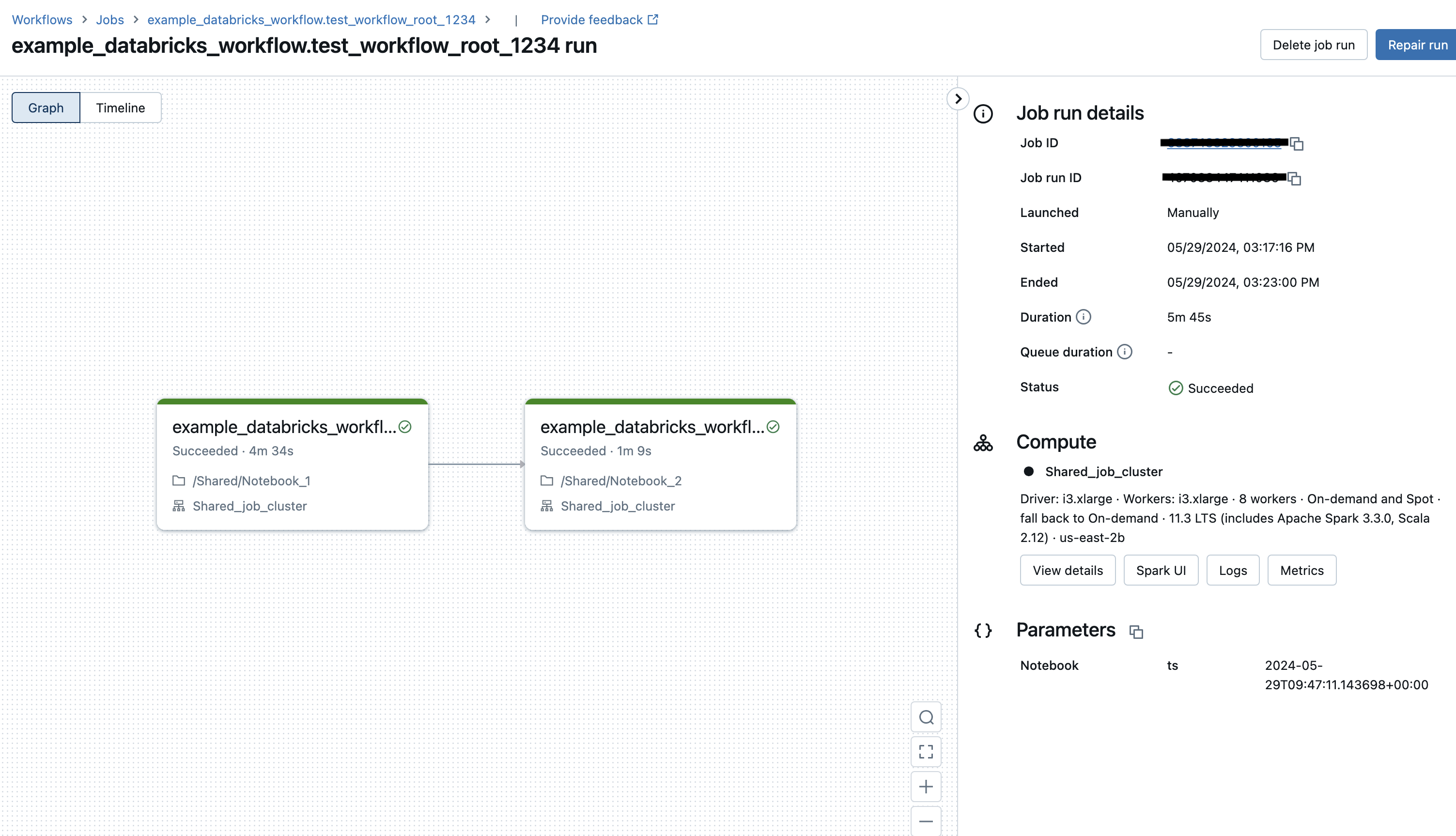
The corresponding Databricks Workflow in the Databricks UI for the run triggered from the Airflow Dag is depicted below¶
To minimize update conflicts, we recommend that you keep parameters in the notebook_params of the
DatabricksWorkflowTaskGroup and not in the DatabricksNotebookOperator whenever possible.
This is because, tasks in the DatabricksWorkflowTaskGroup are passed in on the job trigger time and
do not modify the job definition.