Kubernetes Executor¶
The kubernetes executor is introduced in Apache Airflow 1.10.0. The Kubernetes executor will create a new pod for every task instance.
Example kubernetes files are available at scripts/in_container/kubernetes/app/{secrets,volumes,postgres}.yaml in the source distribution (please note that these examples are not ideal for production environments).
The volumes are optional and depend on your configuration. There are two volumes available:
Dags:
By storing dags onto persistent disk, it will be made available to all workers
Another option is to use
git-sync. Before starting the container, a git pull of the dags repository will be performed and used throughout the lifecycle of the pod
Logs:
By storing logs onto a persistent disk, the files are accessible by workers and the webserver. If you don’t configure this, the logs will be lost after the worker pods shuts down
Another option is to use S3/GCS/etc to store logs
To troubleshoot issue with KubernetesExecutor, you can use airflow kubernetes generate-dag-yaml command.
This command generates the pods as they will be launched in Kubernetes and dumps them into yaml files for you to inspect.
pod_template_file¶
As of Airflow 1.10.12, you can now use the pod_template_file option in the kubernetes section
of the airflow.cfg file to form the basis of your KubernetesExecutor pods. This process is faster to execute
and easier to modify.
We include multiple examples of working pod operators below, but we would also like to explain a few necessary components if you want to customize your template files. As long as you have these components, every other element in the template is customizable.
Airflow will overwrite the base container image and the pod name
There are two points where Airflow potentially overwrites the base image: in the airflow.cfg
or the pod_override (discussed below) setting. This value is overwritten to ensure that users do
not need to update multiple template files every time they upgrade their docker image. The other field
that Airflow overwrites is the pod.metadata.name field. This field has to be unique across all pods,
so we generate these names dynamically before launch.
It’s important to note while Airflow overwrites these fields, they can not be left blank. If these fields do not exist, kubernetes can not load the yaml into a Kubernetes V1Pod.
Each Airflow
pod_template_filemust have a container named “base” at thepod.spec.containers[0]position
Airflow uses the pod_template_file by making certain assumptions about the structure of the template.
When airflow creates the worker pod’s command, it assumes that the airflow worker container part exists
at the beginning of the container array. It then assumes that the container is named base
when it merges this pod with internal configs. You are more than welcome to create
sidecar containers after this required container.
With these requirements in mind, here are some examples of basic pod_template_file YAML files.
pod_template_file using the dag_in_image setting:
airflow/kubernetes/pod_template_file_examples/dags_in_image_template.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: dummy-name
spec:
containers:
- args: []
command: []
env:
- name: AIRFLOW__CORE__EXECUTOR
value: LocalExecutor
# Hard Coded Airflow Envs
- name: AIRFLOW__CORE__FERNET_KEY
valueFrom:
secretKeyRef:
name: RELEASE-NAME-fernet-key
key: fernet-key
- name: AIRFLOW__CORE__SQL_ALCHEMY_CONN
valueFrom:
secretKeyRef:
name: RELEASE-NAME-airflow-metadata
key: connection
- name: AIRFLOW_CONN_AIRFLOW_DB
valueFrom:
secretKeyRef:
name: RELEASE-NAME-airflow-metadata
key: connection
envFrom: []
image: dummy_image
imagePullPolicy: IfNotPresent
name: base
ports: []
volumeMounts:
- mountPath: "/opt/airflow/logs"
name: airflow-logs
- mountPath: /opt/airflow/dags
name: airflow-dags
readOnly: false
- mountPath: /opt/airflow/dags
name: airflow-dags
readOnly: true
subPath: repo/tests/dags
hostNetwork: false
restartPolicy: Never
securityContext:
runAsUser: 50000
nodeSelector:
{}
affinity:
{}
tolerations:
[]
serviceAccountName: 'RELEASE-NAME-worker-serviceaccount'
volumes:
- name: dags
persistentVolumeClaim:
claimName: RELEASE-NAME-dags
- emptyDir: {}
name: airflow-logs
- configMap:
name: RELEASE-NAME-airflow-config
name: airflow-config
- configMap:
name: RELEASE-NAME-airflow-config
name: airflow-local-settings
pod_template_file which stores DAGs in a persistentVolume:
airflow/kubernetes/pod_template_file_examples/dags_in_volume_template.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: dummy-name
spec:
containers:
- args: []
command: []
env:
- name: AIRFLOW__CORE__EXECUTOR
value: LocalExecutor
# Hard Coded Airflow Envs
- name: AIRFLOW__CORE__FERNET_KEY
valueFrom:
secretKeyRef:
name: RELEASE-NAME-fernet-key
key: fernet-key
- name: AIRFLOW__CORE__SQL_ALCHEMY_CONN
valueFrom:
secretKeyRef:
name: RELEASE-NAME-airflow-metadata
key: connection
- name: AIRFLOW_CONN_AIRFLOW_DB
valueFrom:
secretKeyRef:
name: RELEASE-NAME-airflow-metadata
key: connection
envFrom: []
image: dummy_image
imagePullPolicy: IfNotPresent
name: base
ports: []
volumeMounts:
- mountPath: "/opt/airflow/logs"
name: airflow-logs
- mountPath: /opt/airflow/dags
name: airflow-dags
readOnly: true
subPath: repo/tests/dags
hostNetwork: false
restartPolicy: Never
securityContext:
runAsUser: 50000
nodeSelector:
{}
affinity:
{}
tolerations:
[]
serviceAccountName: 'RELEASE-NAME-worker-serviceaccount'
volumes:
- name: dags
persistentVolumeClaim:
claimName: RELEASE-NAME-dags
- emptyDir: {}
name: airflow-logs
- configMap:
name: RELEASE-NAME-airflow-config
name: airflow-config
- configMap:
name: RELEASE-NAME-airflow-config
name: airflow-local-settings
pod_template_file which pulls DAGs from git:
airflow/kubernetes/pod_template_file_examples/git_sync_template.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: dummy-name
spec:
initContainers:
- name: git-sync
image: "k8s.gcr.io/git-sync:v3.1.6"
env:
- name: GIT_SYNC_REV
value: "HEAD"
- name: GIT_SYNC_BRANCH
value: "v1-10-stable"
- name: GIT_SYNC_REPO
value: "https://github.com/apache/airflow.git"
- name: GIT_SYNC_DEPTH
value: "1"
- name: GIT_SYNC_ROOT
value: "/git"
- name: GIT_SYNC_DEST
value: "repo"
- name: GIT_SYNC_ADD_USER
value: "true"
- name: GIT_SYNC_WAIT
value: "60"
- name: GIT_SYNC_MAX_SYNC_FAILURES
value: "0"
volumeMounts:
- name: dags
mountPath: /git
containers:
- args: []
command: []
env:
- name: AIRFLOW__CORE__EXECUTOR
value: LocalExecutor
# Hard Coded Airflow Envs
- name: AIRFLOW__CORE__FERNET_KEY
valueFrom:
secretKeyRef:
name: RELEASE-NAME-fernet-key
key: fernet-key
- name: AIRFLOW__CORE__SQL_ALCHEMY_CONN
valueFrom:
secretKeyRef:
name: RELEASE-NAME-airflow-metadata
key: connection
- name: AIRFLOW_CONN_AIRFLOW_DB
valueFrom:
secretKeyRef:
name: RELEASE-NAME-airflow-metadata
key: connection
envFrom: []
image: dummy_image
imagePullPolicy: IfNotPresent
name: base
ports: []
volumeMounts:
- mountPath: "/opt/airflow/logs"
name: airflow-logs
- mountPath: /opt/airflow/dags
name: airflow-dags
readOnly: false
- mountPath: /opt/airflow/dags
name: airflow-dags
readOnly: true
hostNetwork: false
restartPolicy: Never
securityContext:
runAsUser: 50000
nodeSelector:
{}
affinity:
{}
tolerations:
[]
serviceAccountName: 'RELEASE-NAME-worker-serviceaccount'
volumes:
- name: dags
emptyDir: {}
- emptyDir: {}
name: airflow-logs
- configMap:
name: RELEASE-NAME-airflow-config
name: airflow-config
- configMap:
name: RELEASE-NAME-airflow-config
name: airflow-local-settings
pod_override¶
When using the KubernetesExecutor, Airflow offers the ability to override system defaults on a per-task basis.
To utilize this functionality, create a Kubernetes V1pod object and fill in your desired overrides.
Please note that the scheduler will override the metadata.name of the V1pod before launching it.
To overwrite the base container of the pod launched by the KubernetesExecutor, create a V1pod with a single container, and overwrite the fields as follows:
volume_task = PythonOperator(
task_id="task_with_volume",
python_callable=test_volume_mount,
executor_config={
"pod_override": k8s.V1Pod(
spec=k8s.V1PodSpec(
containers=[
k8s.V1Container(
name="base",
volume_mounts=[
k8s.V1VolumeMount(
mount_path="/foo/", name="example-kubernetes-test-volume"
)
],
)
],
volumes=[
k8s.V1Volume(
name="example-kubernetes-test-volume",
host_path=k8s.V1HostPathVolumeSource(path="/tmp/"),
)
],
)
),
},
)
Note that volume mounts environment variables, ports, and devices will all be extended instead of overwritten.
To add a sidecar container to the launched pod, create a V1pod with an empty first container with the
name base and a second container containing your desired sidecar.
sidecar_task = PythonOperator(
task_id="task_with_sidecar",
python_callable=test_sharedvolume_mount,
executor_config={
"pod_override": k8s.V1Pod(
spec=k8s.V1PodSpec(
containers=[
k8s.V1Container(
name="base",
volume_mounts=[
k8s.V1VolumeMount(mount_path="/shared/", name="shared-empty-dir")
],
),
k8s.V1Container(
name="sidecar",
image="ubuntu",
args=["echo \"retrieved from mount\" > /shared/test.txt"],
command=["bash", "-cx"],
volume_mounts=[
k8s.V1VolumeMount(mount_path="/shared/", name="shared-empty-dir")
],
),
],
volumes=[
k8s.V1Volume(name="shared-empty-dir", empty_dir=k8s.V1EmptyDirVolumeSource()),
],
)
),
},
)
You can also create custom pod_template_file on a per-task basis so that you can recycle the same base values between multiple tasks.
This will replace the default pod_template_file named in the airflow.cfg and then override that template using the pod_override_spec.
Here is an example of a task with both features:
task_with_template = PythonOperator(
task_id="task_with_template",
python_callable=print_stuff,
executor_config={
"pod_template_file": "/usr/local/airflow/pod_templates/basic_template.yaml",
"pod_override": k8s.V1Pod(metadata=k8s.V1ObjectMeta(labels={"release": "stable"})),
},
)
KubernetesExecutor Architecture¶
The KubernetesExecutor runs as a process in the Scheduler that only requires access to the Kubernetes API (it does not need to run inside of a Kubernetes cluster). The KubernetesExecutor requires a non-sqlite database in the backend, but there are no external brokers or persistent workers needed. For these reasons, we recommend the KubernetesExecutor for deployments have long periods of dormancy between DAG execution.
When a DAG submits a task, the KubernetesExecutor requests a worker pod from the Kubernetes API. The worker pod then runs the task, reports the result, and terminates.
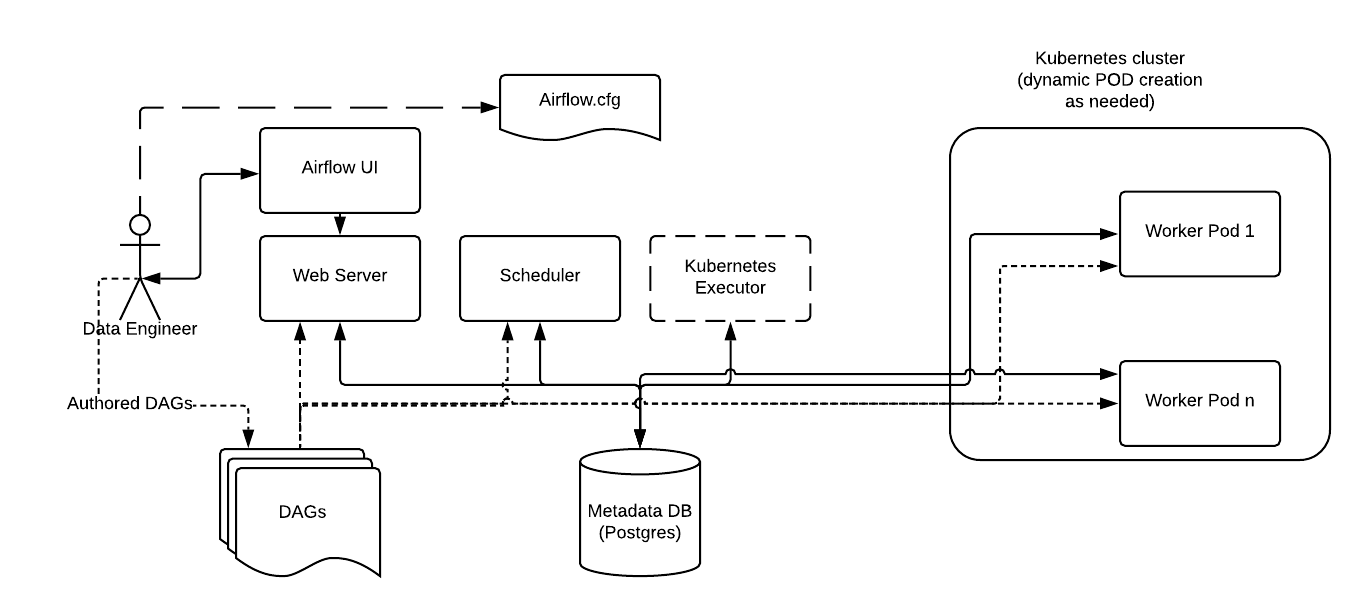
In contrast to the Celery Executor, the Kubernetes Executor does not require additional components such as Redis and Flower, but does require the Kubernetes infrastructure.
One example of an Airflow deployment running on a distributed set of five nodes in a Kubernetes cluster is shown below.
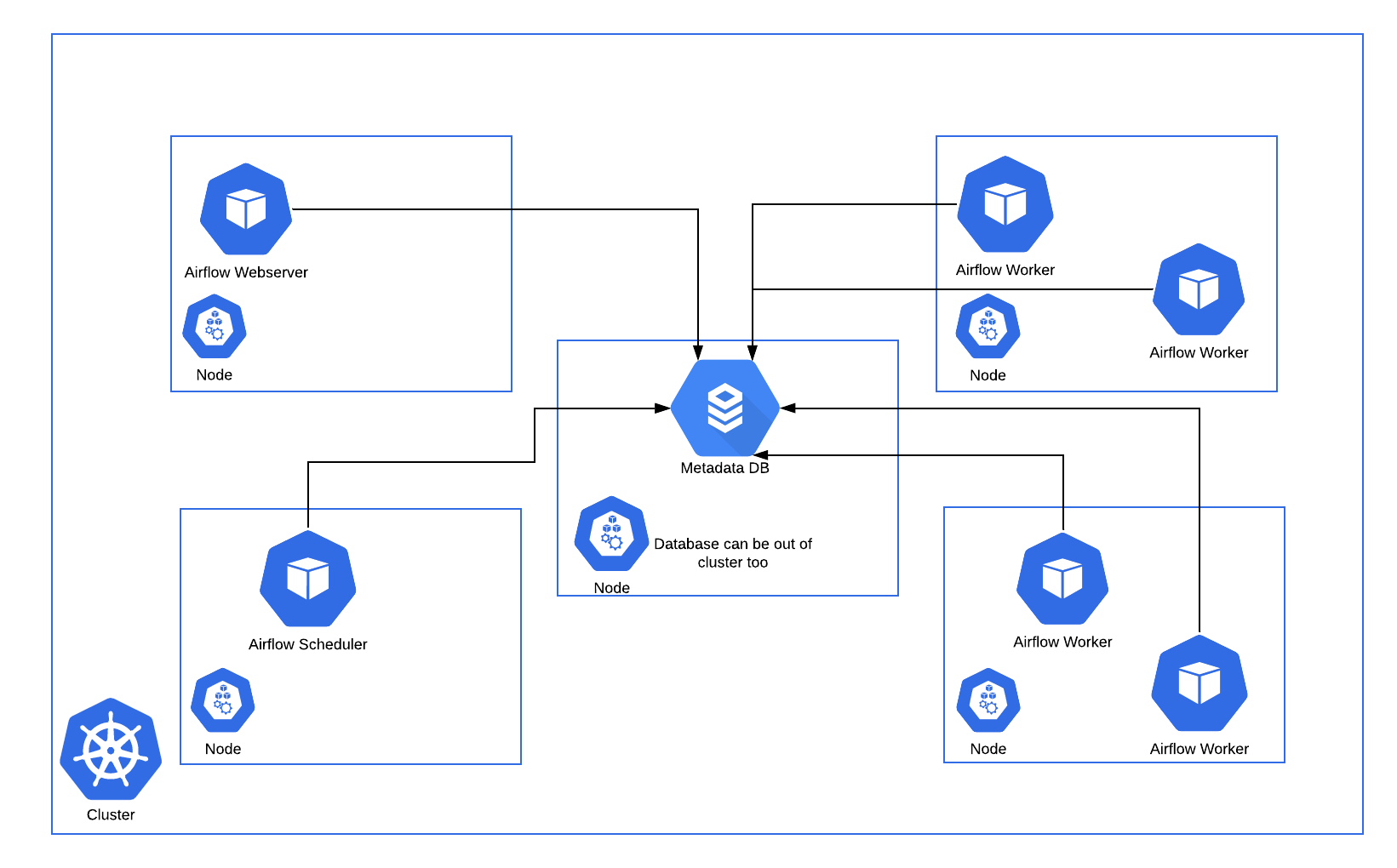
The Kubernetes Executor has an advantage over the Celery Executor in that Pods are only spun up when required for task execution compared to the Celery Executor where the workers are statically configured and are running all the time, regardless of workloads. However, this could be a disadvantage depending on the latency needs, since a task takes longer to start using the Kubernetes Executor, since it now includes the Pod startup time.
Consistent with the regular Airflow architecture, the Workers need access to the DAG files to execute the tasks within those DAGs and interact with the Metadata repository. Also, configuration information specific to the Kubernetes Executor, such as the worker namespace and image information, needs to be specified in the Airflow Configuration file.
Additionally, the Kubernetes Executor enables specification of additional features on a per-task basis using the Executor config.

Fault Tolerance¶
Handling Worker Pod Crashes¶
When dealing with distributed systems, we need a system that assumes that any component can crash at any moment for reasons ranging from OOM errors to node upgrades.
In the case where a worker dies before it can report its status to the backend DB, the executor can use a Kubernetes watcher thread to discover the failed pod.
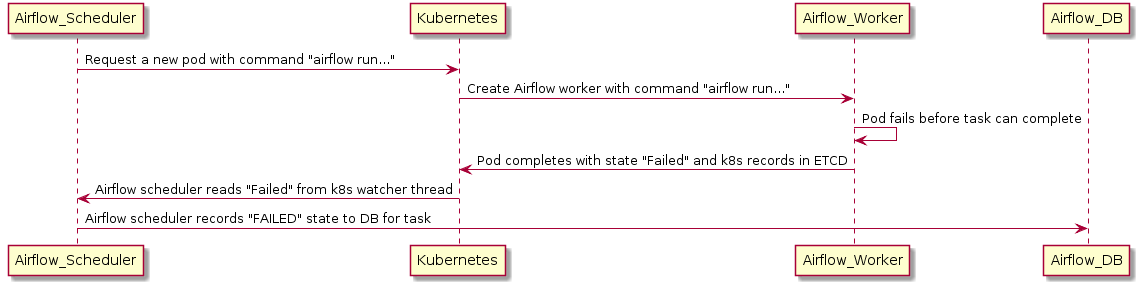
A Kubernetes watcher is a thread that can subscribe to every change that occurs in Kubernetes’ database. It is alerted when pods start, run, end, and fail. By monitoring this stream, the KubernetesExecutor can discover that the worker crashed and correctly report the task as failed.
But What About Cases Where the Scheduler Pod Crashes?¶
In cases of scheduler crashes, we can completely rebuild the state of the scheduler using the watcher’s resourceVersion.
When monitoring the Kubernetes cluster’s watcher thread, each event has a monotonically rising number called a resourceVersion. Every time the executor reads a resourceVersion, the executor stores the latest value in the backend database. Because the resourceVersion is stored, the scheduler can restart and continue reading the watcher stream from where it left off. Since the tasks are run independently of the executor and report results directly to the database, scheduler failures will not lead to task failures or re-runs.