Kubernetes Executor¶
The kubernetes executor is introduced in Apache Airflow 1.10.0. The Kubernetes executor will create a new pod for every task instance.
Dags:
By storing dags onto persistent disk, it will be made available to all workers
Another option is to use
git-sync. Before starting the container, a git pull of the dags repository will be performed and used throughout the lifecycle of the pod
Logs:
By storing logs onto a persistent disk, the files are accessible by workers and the webserver. If you don’t configure this, the logs will be lost after the worker pods shuts down
Another option is to use S3/GCS/etc to store logs
KubernetesExecutor Architecture¶
The KubernetesExecutor runs as a process in the Scheduler that only requires access to the Kubernetes API (it does not need to run inside of a Kubernetes cluster). The KubernetesExecutor requires a non-sqlite database in the backend, but there are no external brokers or persistent workers needed. For these reasons, we recommend the KubernetesExecutor for deployments have long periods of dormancy between DAG execution.
When a DAG submits a task, the KubernetesExecutor requests a worker pod from the Kubernetes API. The worker pod then runs the task, reports the result, and terminates.
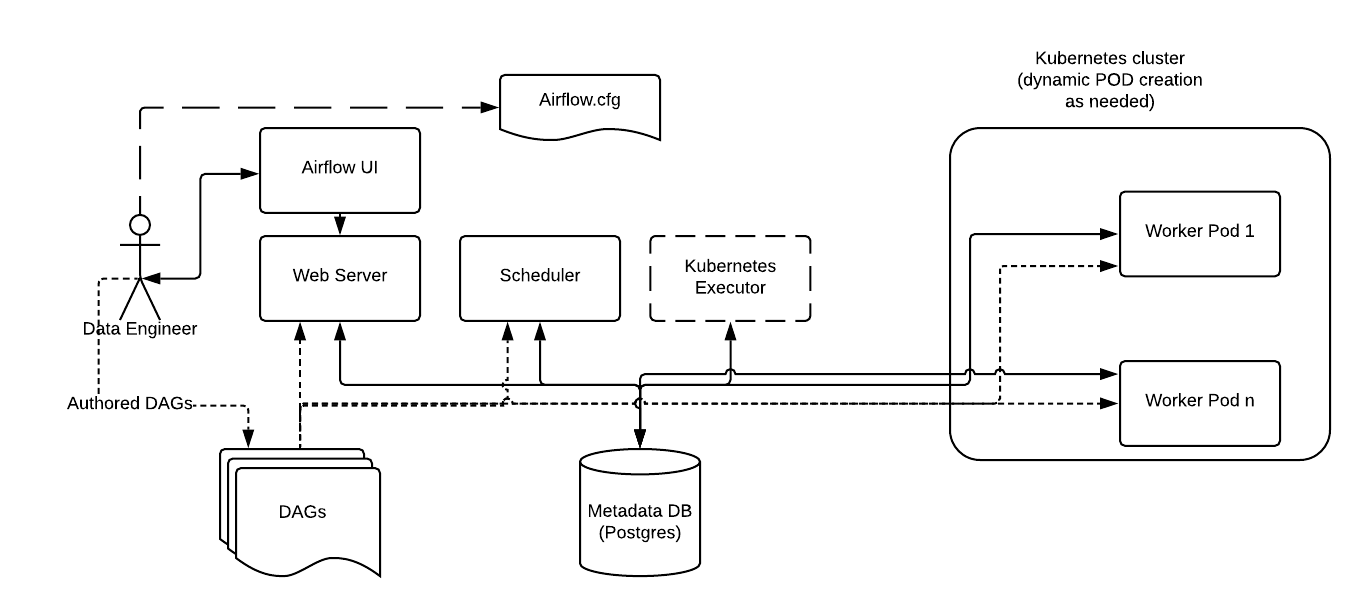
In contrast to the Celery Executor, the Kubernetes Executor does not require additional components such as Redis and Flower, but does require the Kubernetes infrastructure.
One example of an Airflow deployment running on a distributed set of five nodes in a Kubernetes cluster is shown below.
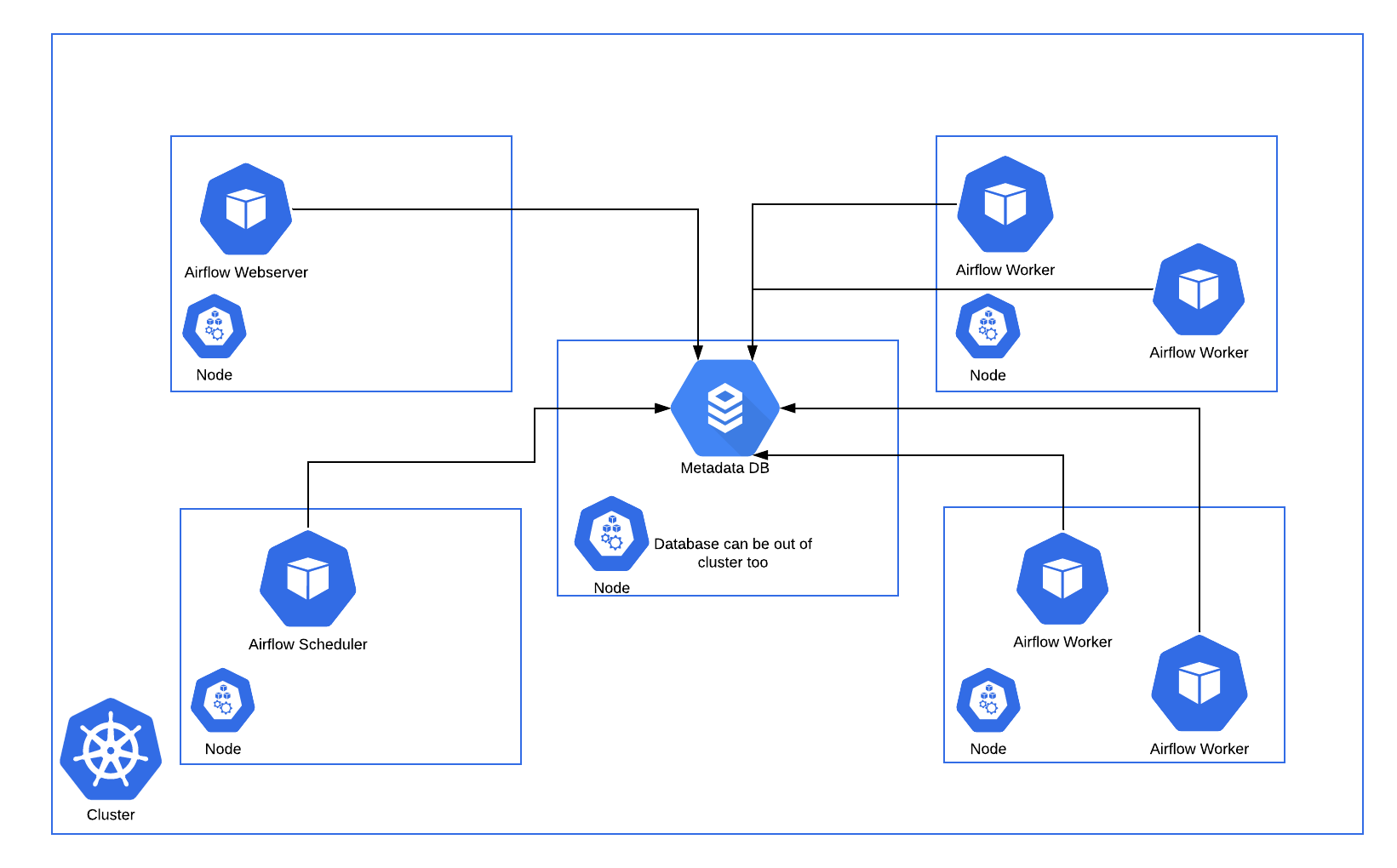
The Kubernetes Executor has an advantage over the Celery Executor in that Pods are only spun up when required for task execution compared to the Celery Executor where the workers are statically configured and are running all the time, regardless of workloads. However, this could be a disadvantage depending on the latency needs, since a task takes longer to start using the Kubernetes Executor, since it now includes the Pod startup time.
Consistent with the regular Airflow architecture, the Workers need access to the DAG files to execute the tasks within those DAGs and interact with the Metadata repository. Also, configuration information specific to the Kubernetes Executor, such as the worker namespace and image information, needs to be specified in the Airflow Configuration file.
Additionally, the Kubernetes Executor enables specification of additional features on a per-task basis using the Executor config.

Fault Tolerance¶
Handling Worker Pod Crashes¶
When dealing with distributed systems, we need a system that assumes that any component can crash at any moment for reasons ranging from OOM errors to node upgrades.
In the case where a worker dies before it can report its status to the backend DB, the executor can use a Kubernetes watcher thread to discover the failed pod.
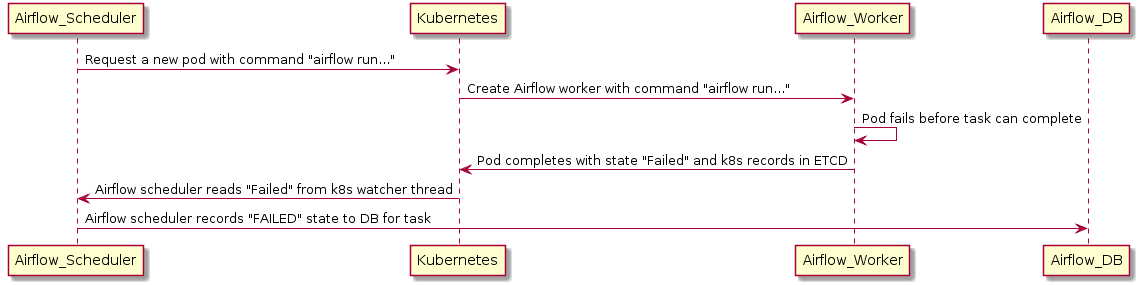
A Kubernetes watcher is a thread that can subscribe to every change that occurs in Kubernetes’ database. It is alerted when pods start, run, end, and fail. By monitoring this stream, the KubernetesExecutor can discover that the worker crashed and correctly report the task as failed.
But What About Cases Where the Scheduler Pod Crashes?¶
In cases of scheduler crashes, we can completely rebuild the state of the scheduler using the watcher’s resourceVersion.
When monitoring the Kubernetes cluster’s watcher thread, each event has a monotonically rising number called a resourceVersion. Every time the executor reads a resourceVersion, the executor stores the latest value in the backend database. Because the resourceVersion is stored, the scheduler can restart and continue reading the watcher stream from where it left off. Since the tasks are run independently of the executor and report results directly to the database, scheduler failures will not lead to task failures or re-runs.