Agentic Workloads on Airflow: Observable, Retryable, and Auditable by Design
A question like “How does AI tool usage vary across Airflow versions?” has a natural SQL shape: one cross-tabulation, one result. A question like “What does a typical Airflow deployment look like for practitioners who are actively using AI in their workflow?” does not. It requires querying executor type, deployment method, cloud provider, and Airflow version independently, each filtered to the same respondent group, then synthesizing the results into a coherent picture. No single query returns the answer. The answer emerges from the relationship between all of them.
This is where Airflow’s agentic pattern begins: not when you add an LLM to a workflow, but when the structure of the work itself depends on running multiple LLM calls whose outputs feed a synthesis step. This post builds that pattern using the 2025 Airflow Community Survey data set and the apache-airflow-providers-common-ai provider for Airflow 3.
If you haven’t read the introductory survey analysis post yet, start there for a walkthrough of the single-query interactive and scheduled pipelines. This post picks up where that one ends.
The Agentic Gap in the Single-Query Pattern
The interactive and scheduled survey DAGs from the introductory post each do one thing: translate a natural language question into SQL, execute it against the CSV, and return the result. The LLM is involved once. The structure of the pipeline does not change based on what that LLM call returns.
That is not a limitation to fix. It is the right design for that class of question. For a large fraction of production AI workflows, a single well-structured LLM call with good context is sufficient and preferable.
The pattern becomes agentic when two things are true simultaneously:
- The question requires querying multiple independent dimensions
- The synthesis step, the thing that produces the final answer, depends on all of those results
In an agent harness framework, this would be handled inside a reasoning loop: the LLM decides to call a tool, receives a result, calls another tool, accumulates context, and eventually produces a synthesis. Each tool call is invisible to any outside observer. If one tool call fails, the loop either retries internally or fails entirely.
In Airflow, the same logic takes a different shape. Each sub-query becomes a named task. The fan-out is Dynamic Task Mapping. The synthesis is a named task with its inputs in XCom. Every step is observable, independently retryable, and logged.
The DAG: example_llm_survey_agentic
The full DAG is in
example_llm_survey_agentic.py.
Question: “What does a typical Airflow deployment look like for practitioners who actively use AI tools in their workflow?”
Task graph:
Seven tasks. Four of them run in parallel. Two LLM calls total: one for SQL generation (four instances), one for synthesis. One human review at the end.
| Step | Operator | What happens |
|---|---|---|
| 1 | @task decompose_question |
Returns a list of four sub-questions, one per dimension. |
| 2 | LLMSQLQueryOperator (mapped ×4) |
Each sub-question becomes one SQL query, translated and validated in parallel. |
| 3 | @task wrap_query (mapped ×4) |
Wraps each SQL string into a single-element list for AnalyticsOperator. |
| 4 | AnalyticsOperator (mapped ×4) |
Apache DataFusion executes all four queries in parallel against the local CSV. |
| 5 | @task collect_results |
Gathers the four JSON results and labels each by dimension. |
| 6 | LLMOperator |
Reads all four labeled result sets and writes a narrative characterization. |
| 7 | ApprovalOperator |
Human reviews the synthesized narrative before the DAG completes. |
Decomposing the Question
decompose_question is a plain @task that returns the list of sub-questions. In this example, the list is static: the four dimensions are hardcoded as strings:
@task
def decompose_question() -> list[str]:
return [
"""
Among respondents who use AI/LLM tools to write Airflow code,
what executor types (CeleryExecutor, KubernetesExecutor, LocalExecutor)
are most commonly enabled? Count an executor as enabled only if the
column value is clearly affirmative. Treat blank, NULL, and negative
values as not enabled. Return the count per executor type.""",
"""
Among respondents who use AI/LLM tools to write Airflow code,
how do they deploy Airflow? Return the count per deployment method.""",
"""
Among respondents who use AI/LLM tools to write Airflow code,
which cloud providers are most commonly used for Airflow?
Return the count per cloud provider.""",
"""
Among respondents who use AI/LLM tools to write Airflow code,
what version of Airflow are they currently running?
Return the count per version.""",
]
sub_questions = decompose_question()
The output of this task, a list of four strings, becomes the input to the expand() call on LLMSQLQueryOperator in the next step. Airflow creates one mapped task instance per list element.
Why keep this static? A dynamic version, where the LLM itself decomposes the high-level question into sub-questions at runtime, is possible and more agentic. It adds an LLM call before any SQL runs, which introduces latency and a failure point early in the graph. For a first example, static decomposition is clearer. The dynamic variant is a follow-on pattern.
SQL Generation: Mapping Over Sub-Questions
LLMSQLQueryOperator.partial().expand() creates one mapped task instance per sub-question. All four run in parallel, each translating one natural language question into validated SQL against the survey schema:
generate_sql = LLMSQLQueryOperator.partial(
task_id="generate_sql",
llm_conn_id=LLM_CONN_ID,
datasource_config=survey_datasource,
schema_context=SURVEY_SCHEMA,
).expand(prompt=sub_questions)
In the Airflow UI, this renders as four task instances: generate_sql[0], generate_sql[1], generate_sql[2], generate_sql[3]. Each has its own log, retry counter, and XCom entry. This is what an agent harness’s parallel tool calls look like when they are made explicit.
Each instance returns a single SQL string. LLMSQLQueryOperator validates the output with sqlglot before returning it. Anything that is not a SELECT statement is rejected.
The wrap_query Bridge
AnalyticsOperator expects queries: list[str], a list because it can run multiple queries in one execution. LLMSQLQueryOperator returns a single str. A small @task bridges the interface:
@task
def wrap_query(sql: str) -> list[str]:
return [sql]
wrapped_queries = wrap_query.expand(sql=generate_sql.output)
This step is an implementation detail, not a conceptual one. Four mapped instances of wrap_query run in parallel, each converting one SQL string into a one-element list. The result is four list[str] values that AnalyticsOperator can consume directly.
Parallel Execution via DataFusion
run_query = AnalyticsOperator.partial(
task_id="run_query",
datasource_configs=[survey_datasource],
result_output_format="json",
).expand(queries=wrapped_queries)
Four mapped instances of AnalyticsOperator run in parallel. Each loads the survey CSV into an Apache DataFusion SessionContext in-process and executes its SQL against it. No database server, no shared state between instances.
This is where independent retry earns its value. If the cloud provider query returns a DataFusion error due to a null value in that column, only run_query[2] fails. run_query[0], run_query[1], and run_query[3] have already succeeded and their results are in XCom. When run_query[2] is cleared and retried, the other three results are preserved.
Collecting and Labeling Results
collect_results gathers all four outputs from run_query (Airflow passes the list of mapped outputs directly) and labels each one by dimension key:
# DIMENSION_KEYS = ["executor", "deployment", "cloud", "airflow_version"]
# Order must match the sub-questions returned by decompose_question.
# Airflow preserves mapped task output ordering by index, so this zip is safe.
@task
def collect_results(results: list[str]) -> dict:
labeled: dict[str, list] = {}
for key, raw in zip(DIMENSION_KEYS, results):
items = json.loads(raw)
data = [row for item in items for row in item["data"]]
labeled[key] = data
return labeled
collected = collect_results(run_query.output)
The output is a dict like:
{
"executor": [{"KubernetesExecutor": "Yes", "count": 847}, ...],
"deployment": [{"How do you deploy Airflow?": "Managed Cloud Service", "count": 1203}, ...],
"cloud": [{"primary_cloud": "AWS", "count": 891}, ...],
"airflow_version": [{"version": "3.x", "count": 412}, ...]
}
All four result sets in one XCom entry. This is the input to the synthesis step.
Synthesis: The Second LLM Call
LLMOperator takes the collected results and produces a narrative. This is the synthesis step, the part of the pipeline that could not exist without all four sub-queries having completed first:
The generate_sql step also receives a system_prompt=SQL_SYSTEM_PROMPT that instructs the LLM on quoting conventions, AI usage filter semantics, and how to handle blank/NULL/ambiguous values. That system prompt is defined once at the module level and shared across all four mapped instances.
synthesize_answer = LLMOperator(
task_id="synthesize_answer",
llm_conn_id=LLM_CONN_ID,
system_prompt=SYNTHESIS_SYSTEM_PROMPT,
prompt="""
Given these four independent survey query results about practitioners
who use AI tools to write Airflow code, write a 2-3 sentence
characterization of what a typical Airflow deployment looks like for
this group.
Results: {{ ti.xcom_pull(task_ids='collect_results') }}""",
)
collected >> synthesize_answer
prompt is a template field, so {{ ti.xcom_pull(task_ids='collect_results') }} renders the full dict at execution time. system_prompt maps to the PydanticAI agent’s instructions parameter, so the framing instruction carries into every token the model generates.
The output, a 2-3 sentence characterization, goes to XCom and then to the final approval step.
Inline HITL alternative:
LLMOperatorsupportsrequire_approval=Trueandallow_modifications=Trueas constructor parameters, viaLLMApprovalMixin. Setting these eliminates the separateApprovalOperatortask and lets the reviewer edit the synthesized narrative directly before approving. Whether to use inline approval or a separateApprovalOperatoris a design choice; both produce the same result.
Walking Through a Run
Step 1: Decompose. Trigger the DAG. decompose_question completes in milliseconds and returns the four sub-question strings.
Steps 2–4: Fan-out. Twelve mapped task instances run: four generate_sql, four wrap_query, four run_query. In the Airflow UI, these appear as three rows of four parallel task instances. Each SQL generation call goes to the LLM; each DataFusion execution runs in-process against the CSV.
![generate_sql[3] task logs showing the LLM-generated SQL query](/blog/agentic-workloads-airflow-3/images/agentic-generate-sql-logs.png)
Each mapped generate_sql instance has its own log showing the prompt, generated SQL, and sqlglot validation.
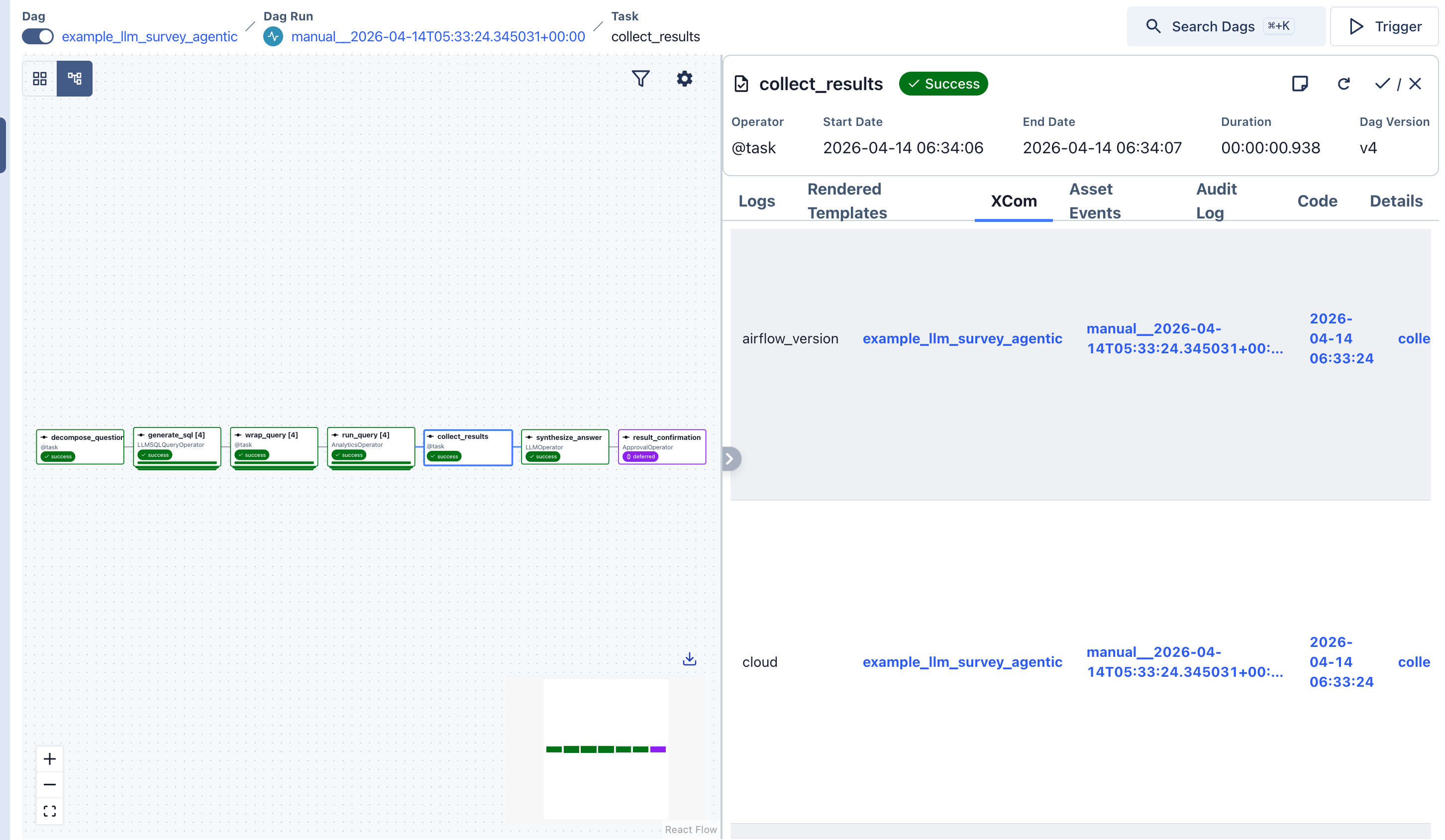
The collect_results task labels each sub-query result by dimension key. All four result sets are visible in XCom.
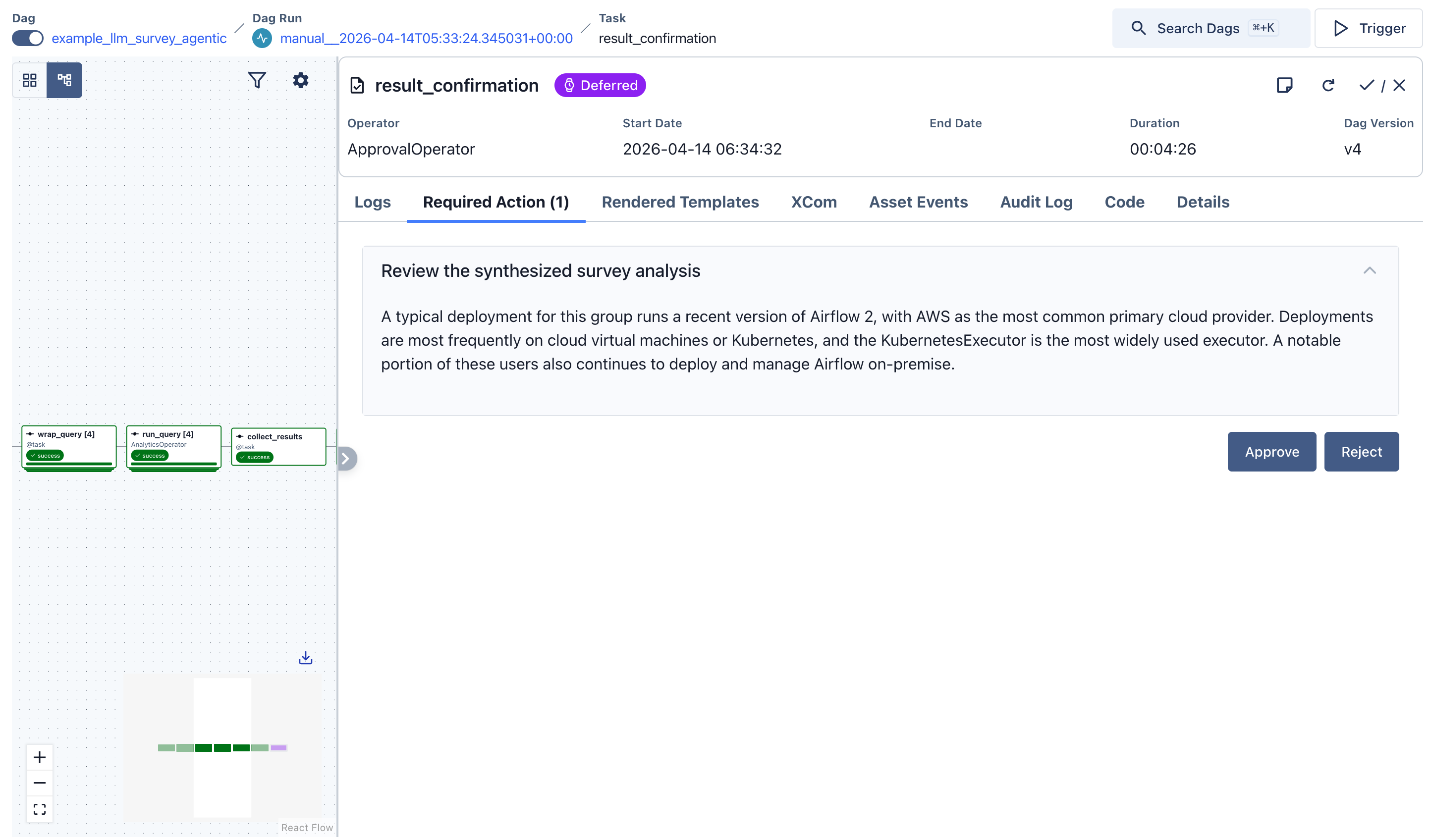
The final ApprovalOperator presents the LLM-synthesized narrative for human review.
A representative generated query for the executor dimension:
SELECT
CASE WHEN "CeleryExecutor" = 'Yes' THEN 'CeleryExecutor' END AS executor_type,
COUNT(*) AS count
FROM survey
WHERE "Are you using AI/LLM (ChatGPT/Cursor/Claude etc) to assist you in writing Airflow code?" != 'No, I don''t use AI to write Airflow code'
AND "CeleryExecutor" IS NOT NULL
GROUP BY executor_type
UNION ALL
SELECT
CASE WHEN "KubernetesExecutor" = 'Yes' THEN 'KubernetesExecutor' END,
COUNT(*)
FROM survey
WHERE "Are you using AI/LLM (ChatGPT/Cursor/Claude etc) to assist you in writing Airflow code?" != 'No, I don''t use AI to write Airflow code'
AND "KubernetesExecutor" IS NOT NULL
GROUP BY 1
-- ... and so on
Step 5: Collect. collect_results assembles the four result sets into a labeled dict.
Step 6: Synthesize. LLMOperator calls the LLM once with all four result sets as context. A representative output:
“Among practitioners who actively use AI tools to write Airflow code, the majority (61%) deploy on a managed cloud service or cloud-native setup, with AWS as the primary cloud provider (38%). KubernetesExecutor is the dominant choice (54%), and this group is adopting Airflow 3.x at a notably higher rate than the survey population as a whole (29% vs. 21% overall).”
Step 7: Review. The ApprovalOperator presents the narrative in the Airflow UI. Approve to complete the DAG; reject to fail it and trigger a retry from the synthesis step if desired.
What the DAG Topology Makes Explicit
The core difference between this pattern and the equivalent agent harness implementation is not the output. It is what is auditable after the run.
| What’s happening | In an agent harness | In this DAG |
|---|---|---|
| Sub-query: executor distribution | LLM internal tool call, no external artifact | Task generate_sql[0]: SQL in XCom, full log |
| Sub-query: cloud provider | LLM internal tool call | Task generate_sql[2]: SQL in XCom, full log |
| Parallel execution | Concurrent or sequential, implementation-dependent | Explicit mapped instances, each on its own worker |
| cloud_provider query fails | Entire run restarts from the top, or fails | Only run_query[2] retries; other three results preserved |
| Synthesis inputs | Accumulated context in the LLM’s reasoning loop | collect_results XCom entry: the exact dict the LLM received |
| Why did it characterize it that way? | No artifact | synthesize_answer XCom: input dict and output string both stored |
Each generate_sql[i] task log contains the prompt the LLM received, the SQL it returned, and the validation result from sqlglot. Each run_query[i] log contains the DataFusion execution details and the row count returned. The synthesis step’s XCom entry contains the exact dict that was passed as context.
This is the same information an agent harness has internally. The difference is that Airflow surfaces it as first-class task artifacts, accessible from the Airflow UI without instrumenting or patching the reasoning loop.
Connecting Your LLM
Both LLMSQLQueryOperator and LLMOperator use llm_conn_id="pydanticai_default". The same connection table from the introductory post applies:
| Provider | Connection type | Required fields |
|---|---|---|
| OpenAI | pydanticai |
Password: API key. Extra: {"model": "openai:gpt-4o"} |
| Anthropic | pydanticai |
Password: API key. Extra: {"model": "anthropic:claude-haiku-4-5-20251001"} |
| Google Vertex | pydanticai-vertex |
Extra: {"model": "google-vertex:gemini-2.0-flash", "project": "...", "vertexai": true} |
| AWS Bedrock | pydanticai-bedrock |
Extra: {"model": "bedrock:us.anthropic.claude-opus-4-5", "region_name": "us-east-1"} |
One connection serves both operators. The synthesis step and the SQL generation steps can use different connections if you want a stronger model for synthesis and a faster one for the SQL generation pass. Set model_id on the LLMOperator to override the connection’s default.
The Multi-Agent Pattern Hidden in Plain Sight
This DAG was not designed around multi-agent frameworks, but it accidentally implements one of the most common separation-of-concerns patterns in that space: the SQL Architect / Critic / Narrator triad.
In agent harness frameworks, these three roles are typically implemented as distinct agent instances that coordinate through an internal routing layer. The underlying rationale is that mixing generation, evaluation, and communication into a single agent produces outputs that are mediocre at all three jobs. Separating them forces each role to reason only about what it is responsible for.
The survey DAG lands in the same place through a different path: the task boundary enforces the separation.
SQL Architect → generate_sql[0..3] (LLMSQLQueryOperator).
Each mapped instance receives one natural language sub-question and produces one SQL query. Schema context is passed as a system-level framing, not as part of the user prompt, so the model reasons about structure before generating syntax. The Architect role is strict: produce a valid SELECT statement or fail.
Critic → two layers.
The first layer is embedded in LLMSQLQueryOperator: sqlglot parses and validates the generated SQL before the task returns. This is a syntax-level Critic: it rejects anything that is not a SELECT. The second and fuller layer is the LLMBranchOperator pattern: an explicit task that evaluates result quality and decides whether the finding is reportable, needs a drill-down, or warrants a pivot to a different hypothesis. That task does what the Critic does in a multi-agent system. It challenges the output rather than accepting it.
Narrator → synthesize_answer (LLMOperator).
Receives the labeled result sets from all four dimensions and produces a plain-language characterization. The Narrator’s role is bounded by design: it receives structured data rows, not the intermediate SQL or any reasoning artifacts, and its system prompt constrains it to communication: “focus on patterns and proportions rather than raw counts.” The role separation is enforced by what is in XCom, not by agent routing logic.
One genuine structural difference remains. In a multi-agent system, the Critic can loop back to the Architect with feedback (“this query has a NULL handling problem, try again”) and the cycle runs until the output meets a quality bar. Airflow DAGs are acyclic. The Critic either raises an exception and triggers a task-level retry of the Architect instance (automatic but blunt), or routes to an alternative path via LLMBranchOperator (explicit and auditable, but the alternative path must be wired in at authoring time). Neither is a pure generative feedback loop.
That acyclicity is a deliberate tradeoff: it is also what makes the DAG’s execution fully auditable and its failure modes predictable. The feedback loop pattern, and the open question of how far it can be supported within a structured workflow model, is part of what Airflow’s roadmap is actively working through.
Try It
The DAG is in the common.ai provider example DAGs:
example_llm_survey_agentic.py.
pip install 'apache-airflow-providers-common-ai' \
'apache-airflow-providers-common-sql[datafusion]'
Requires Apache Airflow 3.0+.
Set SURVEY_CSV_PATH to your local cleaned copy of the survey CSV, create a pydanticai_default connection, and trigger example_llm_survey_agentic.
The Airflow UI will show the four parallel generate_sql and run_query instances fanning out and converging to collect_results. That visual is the clearest way to see what distinguishes the agentic pattern from a single-query run.
Questions, results, and sub-questions that surprised the LLM are welcome on Airflow Slack in #airflow-ai.
Share